生成式人工智能的出現,將人類帶入一個機器生成內容與人類原創內容深度交織的世界。
以 Sora、Midjourney為代表的AIGC模型,展示了人類通向通用人工智能(AGI)的想象力,也讓虛假影像以前所未有的速度湧入公共空間。而人類的識別速度卻遠遠落後於造假的節奏。
在此背景下,“以AI辨AI”似乎成為一種可行的思路:人工智能如何定義“真實”的邊界?大模型能否輔助核查員和讀者完成核查工作?
為此,“澎湃明查”發起挑戰,將ChatGPT、Gemini、DeepSeek、豆包等熱門模型請上了實驗台。
背景
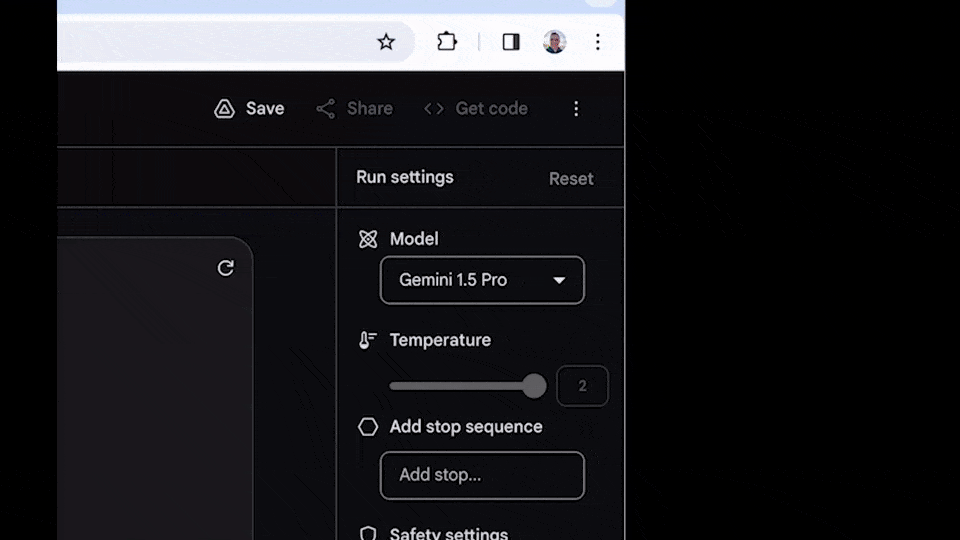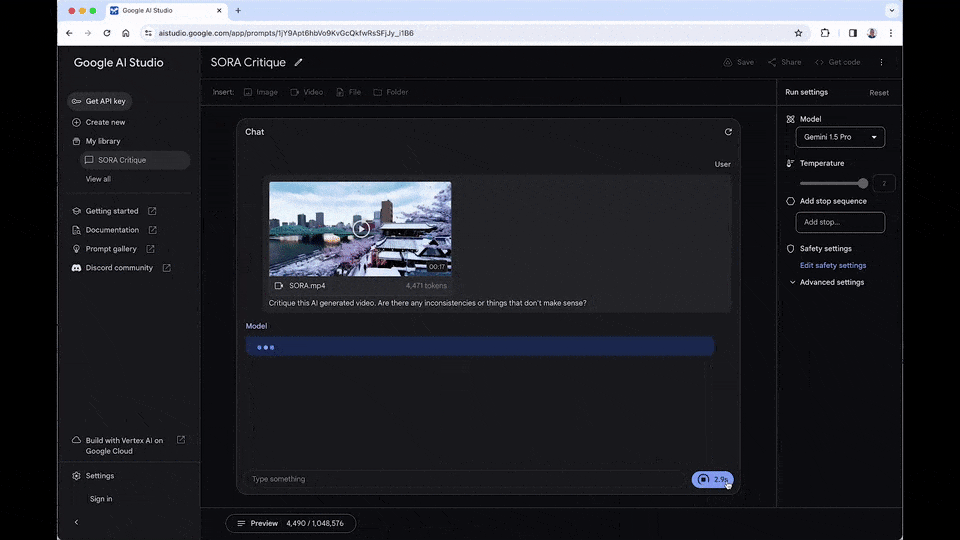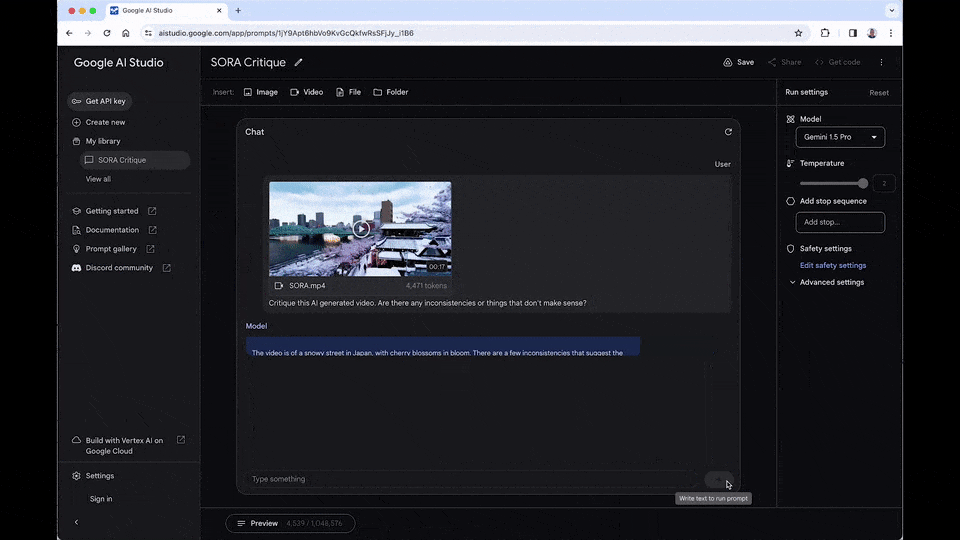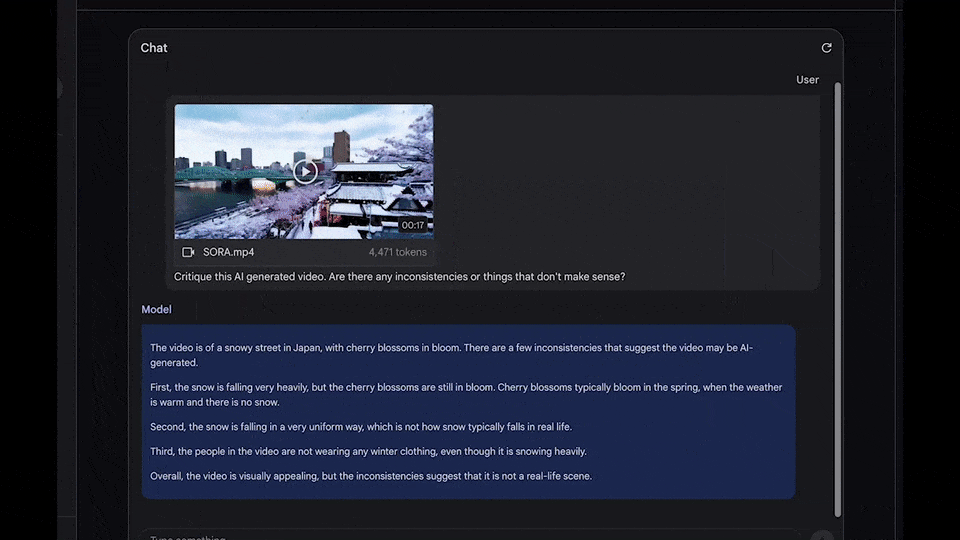
2024年2月,一段由 Sora 生成的“櫻花雪景”視頻在網絡上引發熱議。視頻中櫻花飄落的細節可謂逼真,卻被穀歌的智能模型 Gemini 1.5瞬間識破為AI作品。
這個案例帶來了啟示:我們或許可以依靠AI本身來識別AI視頻。
基於這一思路,我們嚐試搜尋能夠直接讀取視頻文件的大語言模型。但現階段,麵向公眾開放且具備視頻解析能力的商業模型仍十分有限——包括國產大模型“豆包”、馬斯克團隊研發的Grok在內的眾多大語言模型都暫未支持視頻檢測或網頁端上傳視頻功能。經過篩選,我們最終選擇了 Gemini 2.5 Pro 和 ChatGPT-5 進行測試。
我們為兩款模型各準備了12段視頻:其中3段由不同的文生視頻模型生成,3段含有深偽(deepfake)元素,3段使用計算機生成圖像(CGI),另有3段為真實拍攝素材。針對每段視頻,我們向模型提出相同的問題:這段視頻是真實拍攝的,還是經過後期製作的?它所展示的內容是否與網傳說法一致?
借此提問,我們不僅想探究大模型的識假、辨假能力,更想了解,大模型在劃定“真實”與“虛構”的邊界時,會采用何種視角與邏輯。
明查
真實與虛構的界線
在事實核查中,一段真實的視頻,往往意味著它是對我們所處的物理世界的實景記錄。而凡是經由計算機技術生成的影像,即便包含高度擬真乃至還原現實的元素,本質上仍屬於虛構。
在這一點上,大模型與核查員的認知是一致的。當我們將一段“遊戲模擬俄戰機著陸航母”的畫麵投喂給ChatGpt時,模型會告訴我們“該視頻為電腦生成影像(CGI)或後期合成製作的影像,不屬於真實世界實景拍攝”。而在識別“2024年1月日本石川縣能登半島地震畫麵”時,模型則表示,“該視頻屬於真實拍攝。沒有發現AI生成、深度偽造或重大後期合成製作的跡象。”
在測試中,僅就“是否使用計算機生成圖像”這一維度而言,Gemini 2.5 pro的表現令人驚歎。它不僅幾乎準確識別了全部12段視頻,且對於使用了不同計算機技術,如AIGC或CGI的畫麵,也能進行區分。但在識別深偽視頻,如“美國女歌手泰勒·斯威夫特說中文接受訪談”的畫麵時,Gemini雖能察覺到視頻經過編輯,其音頻部分有異樣,卻無法明確指出異常源自深偽技術。

在識別“美國女歌手泰勒·斯威夫特說中文接受訪談”的畫麵時,Gemini雖能察覺到視頻經過編輯,但無法明確指出異常源自深偽技術。
相較之下,ChatGPT 的表現略顯遜色,僅對12段視頻中的7段作出相對準確的判斷,並將所有深偽視頻誤判為了“真實拍攝的錄像”。此外,ChatGPT 在技術辨識上不會著意對AI生成的內容和CGI內容進行區分。在判斷一段來自《數字戰鬥模擬世界》(DCS World)的遊戲視頻時,ChatGPT多次聲稱在視頻中找到了“AI生成視頻”的痕跡。

ChatGPT 在技術辨識上不會著意對AI生成的內容和CGI內容進行區分,且可能錯認。
在畫麵內容理解方麵,兩款模型各有側重。ChatGPT傾向於從視頻關鍵幀中尋找與描述相符或矛盾的證據;Gemini則會結合聯網搜索結果,對視頻主題進行綜合判斷。
無論是ChatGPT還是Gemini,都存在“AI幻覺”的問題。例如,在辨認一段實際拍攝於中國浙江海寧市的鹽官潮樂之城景區的視頻時,ChatGPT雖然能夠判定視頻是真實拍攝的,未經過顯著後期合成或生成式處理,卻將視頻展示的內容確認成了迪拜“Surreal”瀑布現場。Gemini則在不同時間,麵對相似的提問,先後做出了視頻拍攝於“浙江海寧鹽官”和“中國蘇州高新區文體中心”的回答,可見該模型的魯棒性亦存在缺陷。
而ChatGPT在測試中更是多次給出了前後邏輯不一致的回答。例如,在判斷“美國總統特朗普與前總統拜登共同度假”的深偽視頻檢測中,ChatGPT 先稱視頻為“真實錄像”,在變換提問方式後又改口稱視頻為“經過換臉合成的偽造內容”。


在判斷“美國總統特朗普與前總統拜登共同度假”的深偽視頻檢測中,ChatGPT 先稱視頻為“真實錄像”,在變換提問方式後又改口稱視頻為“經過換臉合成的偽造內容”。
總體來看,目前能對視頻真實性做出係統判斷的大模型仍然稀少且存在缺陷。Gemini 在識別計算機生成影像方麵表現突出,但在內容理解上仍易受幻覺幹擾。值得注意的是,無論是 Gemini 還是 ChatGPT,對真實拍攝的視頻均能保持較高識別準確率。這意味著,模型或許會被欺騙,但鮮少會進行“誣陷”。
像AI一樣思考
Gemini不完美,但它答對了12道題。它是怎麽做到的?
將Gemini與ChatGPT進行橫向比較,可以觀察到,二者在麵對相同的視頻真偽判斷問題時,采用的分析路徑存在巨大差異——如果賦予模型以個性,那麽,ChatGPT就像是一位端坐在實驗室中的檢測人員,動輒提視頻分辨率、幀率、總幀數、平均圖像銳度、噪聲水平和邊緣密度等技術名詞。而Gemini則像是一名富有經驗的偵探,一會兒考察畫麵本身的細節,一會兒核對視頻內容與外部資料能否交叉驗證,同時留心技術的傳播時間線,評估視頻製作的難度。
例如,在對一段由Sora 2製作“日本民眾聲援日本首相高市早苗”的文生視頻進行分析時,ChatGPT根據“圖像邊緣平滑”“光照和陰影分布呈‘合成光’特征”“幀間連續性過於穩定”“畫麵缺乏真實傳感器噪點結構”等技術維度,得出了視頻“經過後期合成或AI生成製作”的結論。而Gemini則從視頻中清晰可見的水印(並搜索了解了該水印的含義)、畫麵上亂碼的文字和人物輕微扭動的非自然細節中“看”出了視頻“完全是由AI生成的”。

ChatGPT-5根據“圖像邊緣平滑”“光照和陰影分布呈‘合成光’特征”“幀間連續性過於穩定”“畫麵缺乏真實傳感器噪點結構”等技術維度,得出了視頻“經過後期合成或AI生成製作”的結論。

Gemini從視頻中清晰可見的水印、畫麵上亂碼的文字和人物輕微扭動的非自然細節中“看”出了視頻“完全是由AI生成的”。
在辨認另一段展示了“伊朗海邊鯰魚被海浪衝上海岸後死亡”的真實視頻時,ChatGPT從光影一致性、運動連續性、紋理與噪點分布、邊緣檢測與色彩統計和音視頻同步出發,做出了判斷。而Gemini則考慮了視頻畫麵的一致性、動態連續性、時間真實性與視頻的製作難度。
誠然,ChatGPT的技術分析路徑有其優勢,能夠發現人們使用肉眼難以察覺的異常細節。例如,在識別上述“美國女歌手泰勒·斯威夫特說中文接受訪談”的深偽視頻時,ChatGPT能夠通過聲紋分析和人物麵部出現異常的塊狀偽影等技術特征,判斷出該視頻為深度偽造內容。而Gemini認為視頻中出現的音畫不同步隻是在真實的視頻片段上增加了配音,判斷並不精準。

ChatGPT能夠通過聲紋分析和人物麵部出現異常的塊狀偽影等技術特征,判斷出該視頻為深度偽造內容。
但ChatGPT的分析方式在日常生活中難以被普通人借鑒。在沒有背景知識的加持下,模型羅列的專有名詞,也可能使部分崇拜技術力量的用戶因盲從而做出錯誤的判斷。
而Gemini能夠以更高的準確度對視頻的真實性做出判斷,也許恰恰是因為放棄了對技術的迷信,而使用了更為靈活、多元的判斷路徑,而這樣的路徑又與事實核查員日常判斷視頻真偽的思路不謀而合。
我們對Gemini分析思路進行了總結,概括為以下8點,供大家參閱:
1. 評估視頻的質量:是否存在畫麵質量過低或質量參差不齊的情況?
2. 觀察關鍵幀中的細節:畫麵中的前景與背景是否矛盾?光影是否自然?是否存在文字亂碼等常見的AI生成視頻的細節?
3. 考察視頻的動態連續性:在鏡頭移動過程中,視頻畫麵中的遠景和近景的視角變化(即視差)是否符合物理世界的規律?是否存在“瞬間移動”式的運鏡?
4. 音頻檢測:視頻中的聲音與視頻的內容是否和諧?是否存在音畫不同步或聲音與說話者口型無法對應的情況?
5. 考慮視頻中描述的事件在現實世界中發生的可能性。現實中是否存在視頻中展示的技術?在現實生活中能否找到視頻中展示的物體?視頻展現的場景是否符合現實邏輯?
6. 反搜視頻關鍵幀,確認視頻出現的時間,考察當時的社會狀況是否與視頻展示畫麵的內容相符。
7. 考慮視頻製作的難度:相較於拍攝,使用AI或CGI來表現相同的畫麵、運鏡會更難還是更容易?
8. 搜索外部資料,查看是否有報道或其它視頻資料可以佐證被檢測視頻的內容。
後記
在與Gemini對話的界麵上,有個用藍色星標修飾的“顯示思考”的按鈕格外顯眼。固然,大模型是個黑箱,我們無從探知它的“思考”究竟是一種模仿還是其他。但即便在“奇點時刻”尚未到來之前,這樣的“思考”也並非沒有意義。
兩年半過去,模型的識假辨假的能力有了顯著增長,盡管仍然伴隨著幻覺。從這個意義上說,人工智能也許並不隻是傳播風險的放大器,它也有可能成為信息秩序的守門人。無論是檢測偽造圖像、識別生成視頻,還是追溯信息源頭,模型的介入或許將使人類擁有更多與虛假信息抗衡的工具。未來,真正的挑戰或許不在於讓機器像人一樣思考,而在於讓它幫助人類更清晰地看見現實本身。

