徐令予博客
考槃在澗,碩人之寬。獨寐寤言,永矢弗諼。考槃在阿,碩人之薖。獨寐寤歌,永矢弗過。考槃在陸,碩人之軸。獨寐寤宿,永矢弗告。



數據不支持九章取得了量子計算優勢
作者:徐令予
本係列的前文介紹了 Torontonian 函數的身世,它是一個為了取得“量子優勢”而特地製造出來的數學問題。經過如此煞費苦心的安排,在量子計算機vs超級計算機的對抗賽中,“九章”團隊不僅成了競賽項目和比賽規則的製定者,而且還充當了比賽的裁判員,哨音過後,宣布他們的光學實驗裝置比超級計算機快了100萬億倍(10^14),讓世人著實嚇了一大跳。
這個比賽結果究竟是如何算出來的呢?看完本文的解讀,一定讓你嚇得跳三跳!所有的奧秘就在下麵的三張圖片中,它們分別是“九章”論文的圖3C、圖4、以及附件的圖S28。
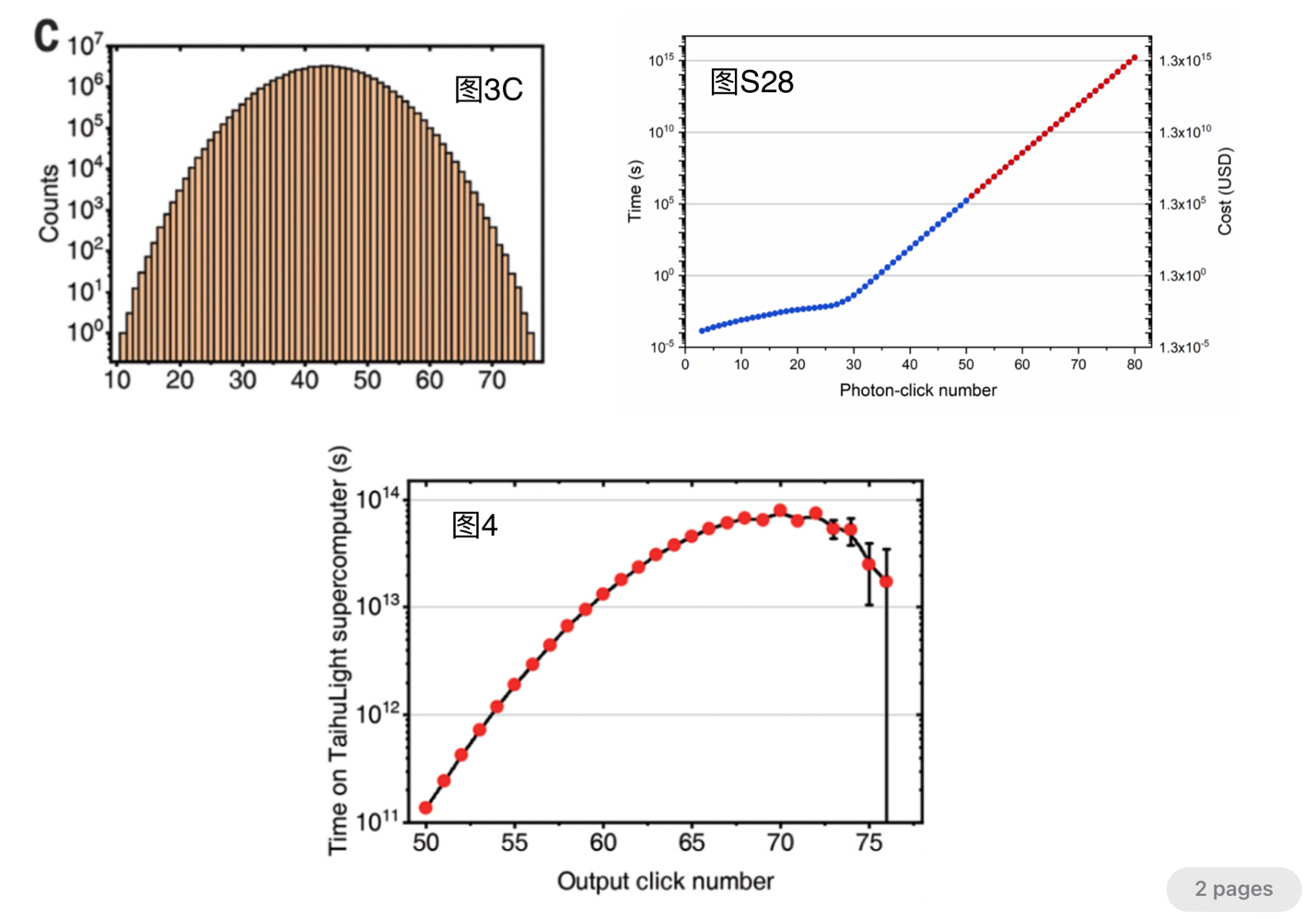
- 圖3C中X軸是光子數,即每次釆樣檢測到有光子(有一個或者一個以上光子到達該出口)的出口的總數,Y軸的值則是在200秒的實驗過程中檢測到光子數為X的樣本總數。例如,檢測到光子數為50的樣本數約為10^6次。
- 圖S28給出了“太湖之光”超級計算機(簡稱超算,下同)通過對100維矩陣的Tor值計算,求得光子數為X的某種分布概率所需要的時間。例如,計算光子數為50的某種分布的概率,超算一共需要10^5秒(從數據輸入到結果輸出)。
- 圖4是依據圖3C和圖S28數據計算得到的。對於圖4曲線上每點的X值,把圖3C中的相對應的Y值與圖S28中相對應的Y值相乘就是圖4中的Y值。例如,當光子數為50,超算需要的總時間是10^6次乘上10^5秒,約等於10^11秒。
最後把圖4中超算對每種光子數計算時間的總和加起來(相當於求出圖4曲線以下的總麵積),約為8x10^16秒,而“九章”隻需200秒,兩者相比得出10^14,“九章”比超算快一百萬億倍就是這樣搗鼓出來的。
但是圖4曲線的產生過程中犯了概念性錯誤。請注意,圖S28的Y值是超算求得有X個光子組成的某種分布的概率所需的時間,而圖3C的Y值是實驗中光子數為X的釆樣總數,它並不是光子數為X的不同的分布數。因為在得到的Y次采樣中,可能有N個樣本屬於同一種分布,它們組成了某一種有效樣本,把N除以實驗的總釆樣數就是該分布的概率,而它對應的就是Tor的一次計算,超算是完全不需要重複計算N次的。另外,在得到的Y次釆樣中,有些分布的樣本又太少,它們不具有任何統計意義應該予以棄除,所以對應這些采樣超算完全不需要浪費任何時間的。
請注意,對於X個光子如果總采樣數是Y,它並不代表有Y種有效的分布,因為有許多次采樣得到的是同一種分布,這恰恰是構成有效樣本所必須的;反之,如果這Y次采樣得到的全是不重複的分布,那麽這些分布由於沒有足夠的樣本數,它們全是無效的。
光子數為X的所有采樣中究竟能有多少有效的分布呢?“九章”的論文對此沒有給出具體的數據,但是不難對有效分布的上限作出估算。根據經典概率理論中弱大數定理,實驗裝置對有效樣本數的采集過程,就是逐漸逼近矩陣Tor的值的過程,可以設置一個最小有效樣本數要求(等效為一個近似誤差門限),例如 10000。因此對於光子數為X的Y次釆樣數,有效分布不可能多於Y/10000。
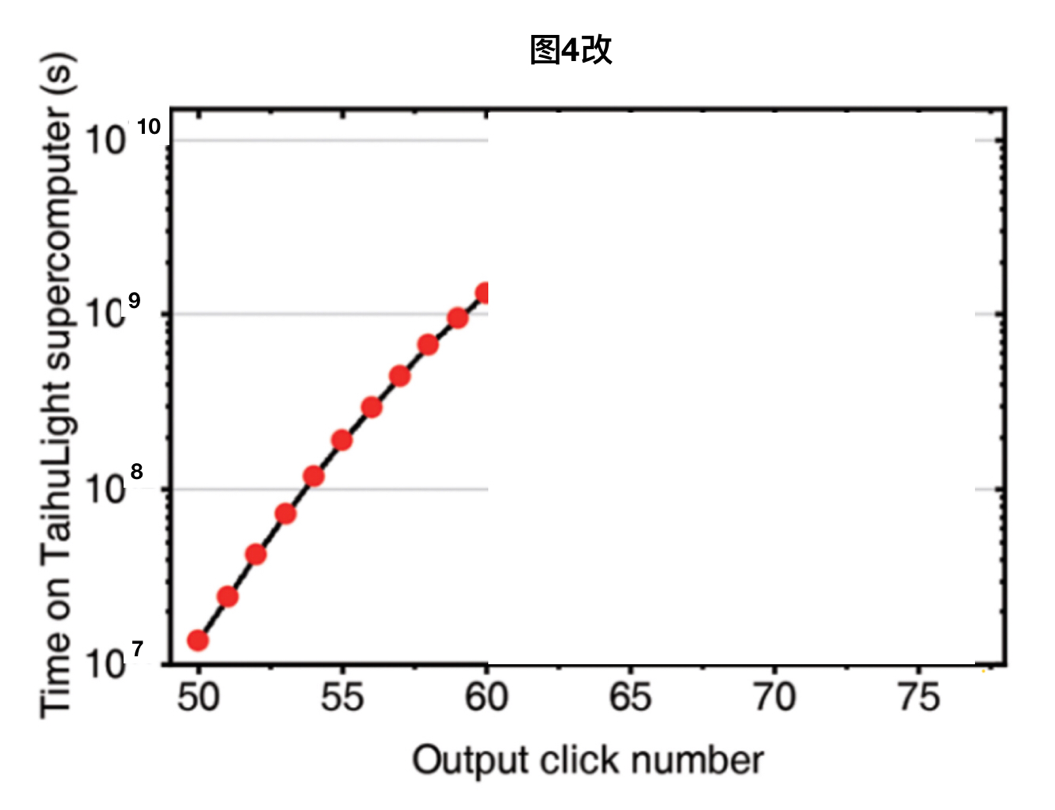
把X個光子的釆樣總數改成有效分布數,並去除所有無效樣本(光子總數大於60後的釆總數一共隻有10000左右,無論何種分布都不可能有足夠的樣本),得到圖4改。對圖4改的曲線求積,超算總開銷不可能超過4x10^9秒。
那麽“九章”得到同樣的結果一共又要多少時間呢?眾所周知,計算總開銷應該包括數據輸入輸出時間和計算時間的總和。“九章”論文中把采樣的200秒等效於計算總開銷,這隻有二種解釋:1)“九章”數據輸入時間極短,相對於200秒可以忽略不計;2)“九章”根本就沒有數據輸入過程。但是第一種解釋違反客觀事實,對於“九章”實驗裝置,100維矩陣參數輸入就是對九章複雜光路的置定、微調和核對,這些都是非常化時間的,輸入時間遠超200秒怎能忽略不計。剩下隻有第二種解釋,對此“九章”團隊是打死也不肯承認的,因為這證實了“九章”不是通常意義上的計算機[1]。
為了擺脫在計算輸入問題上的兩難困境,我為“九章”團隊作出如下辯解:“九章”理論上是可以通過調整實驗設備參數作為數據輸入的手段,雖然實際上會非常困難。數據輸入困難一直就是量子計算機的軟肋,隻是“九章”的情況更為嚴重更為突出。
對於“九章”這樣的實驗裝置,矩陣參數的輸入對應的就是對光路上50個幹涉儀,300個分朿器和75個反光鏡的置定、微調和反複的測試,這個過程究竟要化多少時間實在很難確定,但是對於“九章”實驗數據輸入時間的下限值應該可以作出合理判斷,估計不會低於5整天(約為4x10^5秒)。
超算總時數4x10^9 / 九章實驗總時間(4x10^5+200)約等於10^4,因此“九章”比超級計算機最多也隻快一萬倍。但“九章”論文宣稱快一百萬億倍,足足誇大了一百億倍,想當年,畝產萬斤糧也隻不過誇大了幾十倍,中科大“九章”團隊這次真的是創下了浮誇的曆史紀錄!
事實上,九章”比超算快一萬倍的結論也是完全站不住腳的,問題出在關於速度比較的定義上。九章與超算比速度,比的應該是求取光子在100個出口處的某種分布概率的快慢。當100維矩陣的參數確定下來,光子在100個出口的分布作為自變量給定後,計算機通過求解Tor函數值就可以精確得到該分布出現的概率;九章則通過200秒釆樣,然後得到對應該種分布的樣本數,原則上也可以得近似的統計概率。把這兩者所化時間作比較才是客觀公正的。
但是九章論文偏不這樣計算,他們認為九章在采樣過程中同時還得到了一些其它分布的樣本數,從而可以得到額外分布的概率。九章企圖把釆樣實驗得到的付產品來個廢物利用,要求計算機也得照樣一個個全都算一遍。這好像狂轟濫炸與定點清除比速度,比較的應該是兩者清除既定目標所化的時間長短,但狂轟濫炸派把被自己誤炸亂炸的後果也當作成績來計算,要求定點清除也照樣來上一遍,並把這些時間累加後再作比較,九章團隊實在太不講武德了。
“九章”真要能擊敗經典計算機取得所謂的“量子優勢”,最起碼要能獲得某種有效的光子輸出分布,即對應這種分布至少要取得上萬個相同的樣本。從圖3C可知,符合這個要求的隻可能發生在光子數30~60之間,而從圖S28又可看出,光子數小於50時,計算機對100維矩陣的Tor值求解時間小於“九章”釆樣所需的時間。因此“九章”如果要獲得“量子優勢”的話,應該發生在光子數介於50~60這個狹窄區間中。
但是必須注意,雖然在這個區間有較大的樣本數,但是光子在100個出口處的分布種類更多,更是千變萬化的。例如,50個出口處檢測到有光子,可以是出口1~50檢測到有光子,但也可以是從出口2~51處檢測到光子。這兩個樣本雖然檢測到的光子數都是50,但它們卻代表了光子在100個出口處的完全不同的兩種分布,它們對應的是Tor函數的兩個不相同的自變量,它們的概率是不相同的。
在100個出口處總共檢測到50個光子能有多少種分布呢?這是高中數學中的組合問題,答案是 C(100,50)= 100x99x98....x52x51/50!。這是一個大得非常恐怖的天文數字。雖然九章每次實驗得到50個光子共有一百萬次,但是這50個光子在100個出口處的不同分布的總數要遠遠大於一百萬這個數字。這意味著,對於每種特定的分布,例如,出口處一個隔一個這種分布,很可能在整個實驗過程中一次也沒有釆集到,即使某些分布被檢測到,但是釆樣得到的樣本數少得可憐,它們不具有統計意義。因此在光子數介於50~60這個區間中釆集到一萬個樣本的有效分布的可能性幾乎為零。
歸根結底,當出口處足夠多時(對應於矩陣維數足夠大時),取得一個有效分布是一個小概率事件,九章”實驗的5千萬次釆樣是遠遠不足以獲得有統計意義的結果的[2]。因此,“九章”對經典計算機取得“量子優勢”是沒有科學根據的,這也是國際上許多量子計算專家的共識[3]。
“九章”實驗中釆集到的最多光子數是76個光子,而這樣的事件卻隻測到了一次,這又能說明什麽問題呢?難道76個光子的分布概率是5千萬分之一嗎?這好比你買了十次彩票中了一次大獎,難道可以判定大獎的概率是十分之一嗎?76個光子事件隻能說明“九章”實驗的缺陷和局限性,這種樣本沒有統計意義純屬垃圾數據,但是在“九章”鋪天蓋地的宣傳文章中,卻把76個光子事件吹噓成了世界紀錄,這有點像一個足球運動員把球踢進了自家球門,竟然把這當成戰績到處宣揚,實在令人啼笑皆非。
另外必須強調,忽略計算的正確性和精度的情況下,單純比較計算速度沒有任何意義。“九章”論文中在估計超級計算機求解矩陣Tor值,使用的軟件的字長為256bit,對應這樣的計算精度,“九章”究竟需要多大的樣本數才能與之相配,對此論文也缺失認真的分析和討論。
這讓我想起一個笑話:張三去求職,麵試官李四問他有什麽特長。他說我算術算得特別快。李四就問他,12345乘以67890等於多少?張三說,等於987654321。李四很詫異,這個答案不對啊?張三回答說,別說對不對了,你就說我算得快不快吧?
“九章”量子計算機宣稱比超級電子計算機快一百萬億倍是毫無科學依據的,即使完全按照中科大“九章”團隊自定義的奇葩的比賽規則,他們把戰績至少也誇大了一百億倍!事實上,“九章”的實驗數據不僅無法證明對超級電子計算機取得了量子優勢,恰恰相反,“九章”實驗的真正意義是證明用玻色釆樣獲取量子優勢的路子可能走不通。為什麽這條路走不通?欲知詳情 且看下文分解。
參考文獻
[2] “For real-world data, the result of the Torontonian function is a very small decimal, which results in a high-precision requirement. For instance, when N is 45, the result is 1.44 × 10^-25.”

您不去科學網發文是對的,真受不了那裏慢吞吞的文字審查。