
從深度學習到深度造假,人工智能開始玩殘人類
解濱, CISSP, CISA
人工智能(AI)是不是可以用來殺人?這個問題最近有了答案。答案是:AI不但可以用來殺人,而且殺人的辦法都找好了。
我經常寫點“動態分析”之類的“小報告”,作為 cybersecurity threat intelligence briefing 的一部分。通常我也就是寫點黑客小打小鬧那一類的事。上個星期我講的那件事跟人工智能有關,是一起最近在醫學界和信息世界發生的大事。人類第一次把人工智能(AI)直接進行一項臨床試驗,沒有事先做動物試驗。而這項試驗不是檢驗某項新藥或新技術的療效,而是證明某項新技術可以用來殺人。此事千真萬確。
這項新技術說出來大家並不陌生,這就是“Deep Learning”,也就是AI中的“深度學習”的意思。你以為這項試驗是深度學習如何去治病嗎?錯!恰恰相反,這是深度學習如何去造假,讓醫生出錯,以至於通過醫生的手把病人給殺了。聽上去這是很壞的一件事,但這也是人工智能(AI)的一個新的應用。
這個新技術的概念不難理解。各位都知道,如今在醫院裏使用的MRI和CT都是計算機3D成像,靠計算機把2D掃描結果合成為3D圖像。要讀懂這些3D圖像,需要牢固紮實的專業知識和豐富的臨床經驗,任何疏忽都有可能導致誤診或漏珍,可能造成病人死亡。所以呢,十幾年前就有專家們苦思冥想,試圖依靠AI 來輔助讀片,以提高精準率,減少誤讀。這方麵已經大有斬獲,例如這一篇去年發表的論文
:https://www.ncbi.nlm.nih.gov/pubmed/29777175 。雖然進展可觀,但那距離真正的臨床普及應用還有相當的距離。N年前我給老東家MD安德森打工時曾經做過針對IBM Watson(IBM設計製造的一種智能機器)在醫學上應用的係統的信息安全評估。那個投資十億美元的玩意兒直到今天也還基本上在扯淡。
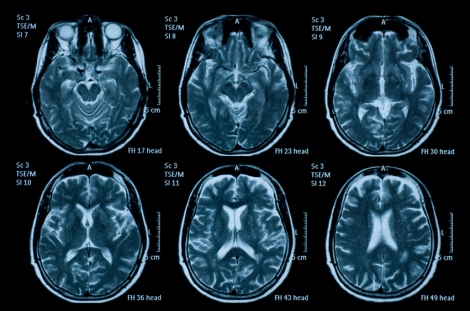
或許是受到來自某種邪惡勢力的靈感的啟發,有人轉而一想,瑪的老子辛辛苦苦幹點正事總是不成,那幹脆整點歪門邪道好了。說做就做!在使用AI輔助診斷還起色不大的同時,用AI在醫學領域進行搗亂破壞的研究卻風生水起,進展迅猛。這不,就在2019年4月3日,一篇驚世駭俗的論文出籠了。三名以色列的研究人員應用AI中的一個重要算法“深度學習”,成功地訓練了一組惡意代碼去偷看醫院放射科網絡(PACS - 圖片存檔和通信係統)中的新生成的MRI或CT圖像。如果在圖像中顯示病人根本就木有患癌症,這惡意代碼就自作主張地弄個癌症放到那圖像中去。那麽如果那些初始圖像表明病人已經患了癌症呢?這一組惡意代碼就自動地、神不知鬼不覺地把癌症從圖像中給抹去。這樣一來,本來沒啥事的病人,被醫生診斷為身患癌症,然後開始進行昂貴和痛苦的治療,去治愈那根本就不存在的癌症。而那些已經患有癌症的病人,會被醫生診斷為“十分健康”,而不采取任何治療措施,直至他們一命嗚呼。

這不是害人嗎?這豈止是害人,簡直是傷天害理!
這一劃時代的研究成果於4月3日發表在一個學術期刊上,其鏈接在這裏:
https://arxiv.org/pdf/1901.03597.pdf
這三位以色列學者治學十分嚴謹。他們把接受試驗的專家們分為兩組。第一組專家,讓他們看的圖像包括造假過的圖像和沒有經過造假的圖像,不告訴這一組經驗豐富的放射專家這些圖像已經魚龍混雜了。結果是,對於那些被植入虛假癌症的圖像,專家們被欺詐的比例是99.2%。對於那些癌症被抹去的圖像,欺詐成功率是95.8% (the attack had an average success rate of 99.2% for cancer injection and 95.8% for cancer removal)。另一組具有同樣資曆的專家們,他們被事先告知他們閱讀的圖像中有些已經被造假,然後讓他們去從那些魚龍混雜的圖像中鑒別真偽。結果呢?那些專家們也是蒙查查,大體上還是無法有效地識別那些假貨,盡管他們個個都是讀片高手[knowledge of the attack did not significantly affect cancer removal (90% from 95.8%). However, the success of the cancer injection was affected (70% from 99.2%).]。
因為事先知道有假,有的專家們還使用了他們的AI軟件進行輔助讀片。結果這些AI讀片軟件也被同樣是使用AI技術的造假代碼給懵了:無法識別出那些深度造假的圖像,其效率甚至還不如人工!
好的AI居然被壞的AI給打敗了!什麽叫邪門呢?這就是!
這件事情很快就在美國醫學界的許多IT工作者中掀起軒然大波。如果這樣的惡意代碼被植入各大醫院的放射科網絡,那麽就意味著將會有成千上萬,甚至上百萬的病人被誤診,乃至於死亡。這豈止是惡意代碼,這簡直就是一場大規模惡意屠殺!
至此,AI開創了一個令人不敢想象的新的功能:玩殘人類。
人工智能(AI)的起源,可以追朔到希臘古代的神話傳說中,技藝高超的工匠可以人工造人,並為其賦予智能或意識。用金屬打造一個人型機器並不難,難的是給這個機器人安裝一個具有人類智慧的大腦。上個世紀40年計算機的發明使一批科學家開始嚴肅地探討構造一個電子大腦的可能性。八十年代,AI蓬勃發展,但課題局限在人機對話,翻譯語言,圖像解釋,機器推理等方麵。當年有些課題早已完成。我們今天使用的穀歌翻譯以及各種翻譯機就是其中一例,其中“深度學習”是關鍵算法之一。過去十年中,得益於大數據和計算機技術的快速發展,AI日趨成熟,開始滲透到越來越多的領域,如生態學模型訓練、經濟數據分析、疾病預測、新藥研發等。其中一個重要的領域“深度學習”極大地推動了圖像和視頻處理、文本分析、語音識別等問題的研究進程。
就跟人類的任何發明既可以造福於人類也可以用於危害人類那樣,或早或晚,或多或少, 新的技術不可避免地會被應用到不道德甚至罪惡的領域。炸藥被用來製造殺人的槍炮, 核能被首先用來製造殺人的原子彈,化工產品被用於製造化學武器,計算機代碼被用來製造計算機病毒,這都是典型的例子。但把AI用於犯罪,一直到兩年前還是僅限於紙上談兵,沒有任何設計方案出籠。一年半以前,一個劃時代的曆史性轉折終於到來,發生在您無法想象的一個領域。
在2017年12月的某一天,在一個叫做“Reddit”的網站上,一個匿名作者上載了一個色情視頻,這個視頻的女主角是Daisy Ridley,她是知名的英國影視演員,《星球大戰》的女主角。幾個小時後這個色情視頻就在網上炸開了鍋。人們幾乎不相信這位馳名歐美影壇的正妹居然會出演一個A片。但沒有誰可以看出這個A片是偽造的,裏麵的女主角無論是聲音還是造型或表情都跟Daisy Ridley一模一樣,讓人無可挑剔 - 就是她!驚恐之餘,當人們看了這個視頻的作者的筆名後,都會心地笑了:“Deepfakes”。這個筆名是“深度造假”的意思。這是從“Deep Learning”(深度學習)衍生過來的一個新詞。這個以假亂真的視頻的製作,就是充分使用了“深度學習”的一個新算法。雖然這一造假技術到了爐火純青的水準,但由於其“產品”畢竟還是個假貨,所以作者還算有點良心,把筆名冠之以“深度造假”。

上麵這是Daisy Ridley在《星球大戰》裏的劇照

這是假的Daisy Ridley在那個色情片中一開始做自我介紹
幾個星期後,“Deepfakes”這個新詞便風靡歐美色情影視產業。為了滿足各位“愛好者”的需求,一個月後第一個根據這個造假術設計的造假軟件“FakeApp”正式出版。這大大降低了deepfake的使用門檻。這個軟件讓用戶很輕鬆地自製換臉視頻,即使你沒有任何人工智能方麵的知識。歐美的知名影視明星和歌星,例如Emma Watson, Katy Perry, Taylor Swift,Scarlett Johansson,統統都被色情技術控們使用深度造假的技術搬上了A片,“消費者”們直呼過癮,爭相先睹為快,一時間好評如潮。

這是Kety Perry被用“Deepfakes”造假的畫麵
不久一批深度造假色情網站如雨後春筍般建立起來。每當“消費者”們質疑那些深度造假的視頻的真實性時,網站站主們都捶胸頓足地表示其來源“絕對可靠”,“這是那些大V們手下的技工們偷拍,然後不小心泄漏出來,本網站忍痛花重金購買,廉價呈現給各位,賠本賺吆喝”雲雲。與此同時,傳統的色情網站門庭冷落。正牌的,循規蹈矩的色情網站受到Deepfake video的嚴重威脅,生意驟減,老牌色棍們對於這一波利用最新AI技術造假之輩嗤之以鼻,痛斥其之為“new breed of sexual abuse”。老牌色情網站紛紛聯合起來抵製那些Deepfake videos,以保證A片的“純潔性和真實性”。甚至就連那些跟色情視頻八杆子打不到半點關係的大牌社交網站如推特、臉書也開始加盟抵製 Deepfake videos。

一年多過去了,人們對於 Deepfake video的新鮮勁大不如前(是不是能造假的臉都被造光了?)。然而人們對於 Deepfakes 這件事本身的熱情卻日漸高漲。根據本人的觀察,幾乎在所有的深度學習可以涉足的領域,深度造假都可以大顯身手,有時甚至可以青出於藍。本文一開始講的這件事就是一個很好的例子。當deep learning在醫學輔助診斷方麵還在一籌莫展的時候, deepfakes 在醫學領域裏已經紅杏出牆,花枝招展了!
說起來確實有點尷尬,AI的這項重大突破居然來自於一個肮髒的、令人不齒的角落。但那不過是深度學習的一個應用,其算法都是一樣的。一樣技術,隻有用起來才能發展和改進。誰說壞的初衷就一定不可能帶來好的結果呢?
Deepfakes這一技術即可用來做好事也可用來做壞事。這一技術可以讓那些因ALS(肌萎縮側索硬化)或癌症等疾病失去聲音的人恢複演講。自動駕駛軟件首先可以在虛擬環境中接受培訓。好萊塢可以用這種技術攝製高度驚險或美若仙境的大片,而不用擔心高昂的成本。一些已經過世的知名演員如麥克傑克遜可以被重新搬上銀幕,唱出新歌。這種技術使用在人機對話裏,可以逼真地模仿某位知名人士的語音回答用戶的問題。壞人可以用Deepfakes 偽造視頻,製造假癌症和隱瞞真癌症,打造出以假亂真的新聞圖片和視頻新聞,塗改穀歌地圖,把拿電子顯微鏡圖片給修改掉,甚至把GPS的數據給塗改掉。騙子和政治極端分子將使用這種深度學習算法生成數不清的虛假信息(例如偽造某位政治人物的性醜聞,私房話,“通俄”錄音等等)。通常社交網絡有選擇地傳播最吸引眼球的內容,這些深度造假係統輸出的內容將演變為最受歡迎的,並被廣泛分享出去。實際上,很多種新的Deepfakes造假產品可能已經被研發出來了,隻是你我還不知道而已。或許在明年的大選中就會有一批“新產品”麵世。
說到這裏,您是不是想知道究竟什麽是“深度學習”呢?請注意本文前麵引用的那篇論文的標題是:“CT-GAN: Malicious Tampering of 3D Medical Imagery using Deep Learning”。這裏的第一個關鍵詞是“GAN”,這是Generative Adversarial Network的縮寫。這個算法是深度學習領域裏革命性的突破。這是GAN之父Ian Goodfellow 於2014年發明的。GAN翻譯成中文就是“對抗生成網絡。”

GAN
GAN 是AI裏麵“非監督式學習”的一種算法,其基本原理是它有兩個模型:一個生成網絡G(Generator),一個判別網絡D(Discriminator)。判別網絡的任務是判斷生成網給定圖像是否看起來‘自然’,換句話說,是否像是人為(機器)生成的。而生成網絡的任務是,生成看起來‘自然’的圖像,要求與原始數據分布盡可能一致。為了便於您對GAN的過程做一個簡要的了解,我虛構了下麵這段不大恰當的對話來簡要地示範一下:
太太:喂,老公,你看我長的像不像範冰冰?
老公:滾!
太太:老公你又在外麵泡上哪個妞了,幹嘛對我這麽凶嘛?
老公:我誰都沒有泡。不是我打擊你的積極性,太太你實在不像範冰冰,差太遠了。當然,盡管如此,你老公我也是愛你的,誰叫你老公這麽沒用,不是那個誰呢?
太太:哼!那我整容去!
三個月後,鼻梁整容好了。
太太:老公,現在我像不像範冰冰了?
老公:有進步但還有差距。就說你下巴,有範冰冰的下巴那麽尖嗎?跟一盤豬頭肉似的。
太太:哼!
六個月後,下巴整容好了。
太太:老公你看,現在我跟範冰冰一模一樣了吧?
老公:不行不行,橫看豎看總覺得哪裏就是不一樣,我也說不出來。
太太:那你去好好看看範冰冰到底長的是啥樣子嘛。
老公剛想敷衍,突然看見一則新聞:“我漂亮嗎?美國臉盲男子不吭聲被妻暴揍”,頓時嚇出一身冷汗,怕自己臉盲被太太大人揍扁,於是趕緊下載了範冰冰的兩個視頻看了N遍,終於發現了太太的臉究竟為什麽咋整都整不成範冰冰,然後跟太太提出了專家級的指導意見。
經過反反複複多次這樣“校正”,終於在做完最後一個手術後的某一天,老公把太太一把抱在懷裏:“太太我愛S你了”
……
上麵這個過程,就是一個 GAN 訓練的過程(大體就是這樣,很多細節忽略了哈)。在這個虛擬的訓練過程中,“太太”就是生成網絡,“老公”就是判別網絡。生成網絡的目的是造樣本,它的目的就是使得自己造樣本的能力盡可能強,強到什麽程度呢,你判別網絡沒法判斷我是真樣本還是假樣本。判別網絡的目的就是來識別一個樣本,看看它是來自真樣本集還是假樣本集。生成網絡從潛在空間(latent space)中隨機采樣作為輸入,其輸出結果需要盡量模仿訓練集中的真實樣本(“範冰冰”)。判別網絡的輸入則為真實樣本或生成網絡的輸出,其目的是將生成網絡的輸出從真實樣本(真的範冰冰的玉照和視頻)中盡可能分辨出來。而生成網絡則要盡可能地欺騙判別網絡(不斷整容)。兩個網絡相互對抗、不斷調整參數,最終目的是使判別網絡無法判斷生成網絡的輸出結果是否真實(太太整容整的跟真的範冰冰一模一樣了)。

GANfather Ian Goodfellow
這個例子裏,太太每整容一次,就相當於生成網每生成一個新的樣本。老公作為判別網就判別一次,說那還不行。生成網絡就不服了,說別瞧不起我,我也很牛叉,不信我再生成一個假樣本給你看看。於是太太就再次整容,巧妙地包裝,非要讓老公(判別網)無法判斷我是真範冰冰還是假範冰冰。就這樣反複循環,直到最後判別不出區別來了。這叫“納什平衡”(Nash equilibrium)。
在這個算法中,生成網跟判別網的目的是相反的:一個說我火眼金睛,能夠判別你的真假;另一個說我魔高一丈,偏要讓你判別不出真假。但判別網絡也不是白吃幹飯的,也在不斷改進(上網下載範冰冰的視頻做參照)。
GAN的強大之處就在於它模擬了真實世界中的過程。這種過程在真實世界中也是最優化的。無論你用它來進行仿真還是造假,這都是到目前為止最厲害的算法。

GAN的簡要示意圖
讀者或許一開始閱讀本文時就有一個大大的問號:那三個以色列學者是不是吃飽飯撐的,沒事幹居然去研究如何使用AI作案,幹嘛不去做點正經八百的好事?這傷天害理的事情居然可以作為學術論文發表,給網上的壞蛋們通風報信。有人報案了嗎?那三個家夥被抓起來了嗎?那篇論文被撤了嗎?我的答案是:那三位學者用他們的研究成果可能救了成千上萬病人的命!利用AI作案,危害人類,這隻是早晚的事。與其坐等壞人暗中發展AI武器,還不如及早把AI可能作案的途徑都給找出來,及早預防。筆者至今還清楚地記得,2000年5月5日那一天, Love Bug worm在全球爆發,把人類打了個措手不及,導致五千萬電腦裏的文件被刪除,成千上萬個公司停產的那個場麵。愛因斯坦在導出E = mc2這個公式後意識到原子彈的威力,他立即寫信給羅斯福,提醒納粹製造原子彈的可能性,建議美國趕在納粹之前造出原子彈。幸虧愛因斯坦的提醒,盟軍及時炸毀了納粹的核試驗裝置。不然的話,人類曆史將不會是今天這樣。我們或許就不可能出生,或許在做法西斯占領軍奴役下的亡國奴。
實際上,識別或防止深度造假的技術已經被發展出來,但要根據不同的種類采用不同的辦法。識別Deepfake videos (深度造假視頻),有一個訣竅,就是觀察眨眼。人類一般每兩秒到十秒之間要眨眼至少一次,而且是有規律的。但在深度造假的過程中,對眨眼的鏡頭是不進行深度學習的。這就造成那些深度造假視頻裏麵的“假人”幾乎不進行正常的眨眼。根據這個,設計一個程序,捕捉眨眼的瞬間,計算一下,就可以發現貓膩。這個方法是紐約大學奧本尼分校的三位華人學者發現的,這是他們的論文的鏈接:https://arxiv.org/pdf/1806.02877.pdf 。至於如何防止那三個以色列專家發明的方法對醫學圖像深度造假,其技術都已經是現成的,這就是“深度加密”:(1) 給每一個原始圖像進行電子簽名(digital signature)以防篡改,(2) 把放射科的網絡統統給加密(end-to-end encryption), 以防偷看。完事。要防止衛星地圖被非法篡改,可以使用同樣的辦法。不久的將來,視頻和圖片生成後,大多會進行電子簽名和加密。誰先發明了能夠放篡改和防造假的機器,誰就占領了先期市場。
雖然牛津字典還沒有收入“Deepfakes”這個新詞,雖然“Deepfakes”這個詞在本文發布之前還沒有被正式翻譯成中文,但深度造假的概念實際上已經開始深入人心。估計半年後穀歌翻譯就會把Deepfakes翻成“深度造假。” 現在有人將其翻譯成“AI變臉”,這是不精確的。因為Deepfakes 應用的範圍遠不止變臉。
美國民主黨有一個2020總統大選候選人(據說還是個“華人”),他認為人工智能(AI)終將導致大批工人失業,所以聯邦政府應該發給每一個美國人每年1萬2千美元的“universal basic income。” 楊總統把AI想得太簡單了。
是的,AI確實可能導致某些人失業,但也將帶來很多的就業機會呀!
不錯,AI確實可以幫助人類解決許多難題,但也可能給人類帶來新的危機。
對的,AI可以用來給人類看病,但也可以被用來殺人。
結論:AI可以用來幹很多好事,也可以用來幹很多壞事。並非隻會讓工人失業。
建議楊總統在兜售他的“AI造成大規模失業”這一理論之前花個至少半天的時間跟一位叫吳恩達(Andrew Ng)的華人專家好好請教一下究竟什麽是AI,AI對我們社會今後的發展將會有哪些影響,等等。不要不懂裝懂。

華人AI大牛吳恩達 Andrew Ng (不是Andrew Yang 的兄弟)
看看AI對於美國色情工業的大舉入侵,那導致誰失業了嗎?就說這三個以色列研究人員在Deepfakes的醫學方麵的最新應用,會導致誰失業嗎?我怎麽覺得剛好相反,job更加穩定了!
那麽如何提前防止人類使用AI殺人呢?我們知道,在生物技術發展方麵,各國都建立了道德委員會,設立了許多“禁區”,不許科學家們涉足。但在AI的發展方麵,現在全世界沒有任何一個道德委員會,今後也不會有。為什麽會是這樣呢?因為生物技術需要高額的投資和嚴格的工作場合,還有高度專業的技術。你沒法在車庫裏進行克隆人的實驗,普通人玩不起。但AI沒有這些條件限製,任何一個高中生都可以在自家車庫裏用老爸算稅的電腦來進行深度造假,低投資高效益(當然那個電腦必須有一個高級一點的GPU哈,不要跟我那台電腦上的那樣濫)。人類可能沒有任何東西能阻止即將到來的人工智能生成的內容。人工智能是把雙刃劍。隨著它的改進,它將能夠模仿人類的行為。最終,它會變得和人非常像:善與惡的能力不相上下。
常言道,耳聽為虛,眼見為實。美國人常說:The cameras don’t lie。有了Deepfakes,這兩句話都不再生效了。AI已經把“眼見為實”打得沒有招架之力了。
聖塔克拉拉大學法學院教授 Eric Goldman 說,我們最好為一個真假難辨的世界早做準備,但事實上,我們已經身處在這樣一個世界中了。

理論物理學家霍金(Stephen Hawking)在五年前說過,人工智能目前的初步階段已經證明非常有用。但他擔心創造出媲美人類甚至超過人類的東西將要麵對的後果。“它可能自行啟動,以不斷加快的速度重新設計自己。而人類局限於緩慢的生物進化過程,根本無法競爭,最終將被超越。” “人工智能的崛起是人類曆史上最好的事情,也有可能是最糟糕的。” 他認為,“人工智能也有可能是人類文明史的終結,除非我們學會如何避免危險。”
把這一席話翻成通俗文字就是:人腦可以玩電腦,或許有一天,電腦也可以玩人腦,搞不好甚至玩殘人腦,乃至於玩殘人類!這就要看我們怎麽玩了,嘿嘿。
這一天是不是已經開始了?
最後我鄭重聲明一下,本文的寫作全部靠筆者的手工和人腦完成,沒有使用任何AI,電腦隻是用來閱讀相關論文和打字的,不負責思維。要轉載本文請聯絡本人:bxie1@yahoo.com。