
五、偽民主製度與神經網絡
讓我們先把圍棋的話題岔開,繞到兩個風馬牛不相及的問題上。不過這裏討論的可不是什麽政治製度問題,而是想以一種假想的代議投票機製為例把神經網絡的基本原理說清楚。
神經網絡,這個當今人工智能領域裏炙手可熱的名詞,既充滿神秘感又給人以無窮的想象。人工智能專家宣稱,神經網絡是模仿人類智慧大腦中的生物學網絡搭建而成,可以通過接受訓練而產生新功能,具有自我學習、糾錯和進化的能力。這類描述帶給人的感覺是神經網絡可以像小孩子一樣學習新鮮事物,從不懂到懂,從懂到專業,從專業到更專業,直至最終超越人類。
大量基於神經網絡技術的產品的問世也似乎在證明這一點:穀歌的物體識別技術已經能夠輕鬆地識別出混雜在同一張照片中的不同物體;各種能聽懂人類語言的電子產品正在悄然進入我們的日常生活之中;最新的智能遊戲機能夠看懂人的不同姿勢和動作……
很多初次接觸神經網絡的人都會覺得這實在是一門讓人神經錯亂的學科:介紹這種技術的書籍往往首先會將神經網絡與人腦的神經係統相比較,指出其相似性,然後就突然祭出一大堆專有名詞和數學公式,似有不把讀者推入五裏霧中誓不罷休之感。
然而,即使是那些經過多年苦行,對神經網絡早已大徹大悟的學者們在向新人介紹這一概念時,似乎也會忘記當年自己的神經是如何被它苦不堪言地折磨,照例搬出大量專有名詞及晦澀的數學公式為其罩上一層又一層的麵紗。
究其原因,恐怕就是因為神經網絡的學習過程完全是“暗箱操作”。人工智能專家可以訓練一個網絡做各種各樣神奇的事情,然而如果要問在這個學習過程中,網絡中哪個參數的變化直接導致了輸出結果的更優化,恐怕沒有人能說得清。正因為如此,人們對神經網絡的認識,隻能停留在非常膚淺的與人類大腦結構的物理相似性之上。
其實,隱藏在神經網絡背後的基本思路非常簡單,因為其運行機理,很容易用當代人非常熟悉的代議製民主製度來解釋清楚。
讓我們來假想一種代議製民主製度。在這種製度中,選民手中的選票並不能直接決定一個議案的通過與否。但這些選票能影響議員投讚成票或反對票而最終導致議案的成敗。
讓我們把問題做一次簡化,假定直接投票的選民總共有五人:一個白人、一個印第安人,此外,亞裔、非裔、拉美裔各一名。這些人的政治理念不同,對於每個議案的投票也會有自己的選擇。
假定議員共有三人,分別是A、B和C。每個議員可以聲稱自己會代表一個或多個選民的利益。例如,議員A聲稱自己代表白人和亞裔的利益,而議員B則聲稱自己代表非裔和拉美裔的利益。
投票的過程是這樣的:選民投票之後,議員必須根據選民的投票結果決定自己是投讚成票還是反對票。不過,議員在做出自己的決定時,隻會考慮自己所代表選民的投票情況:隻有在讚成票數達到或超過半數以上時,該議員才會投讚成票,反之則必須投反對票。
例如,議員A聲稱自己代表白人和亞裔的利益,在投票時他不會去看印第安人、非裔和拉美裔的投票結果。隻要白人或亞裔有一人投讚成票,議員A就會投讚成票;隻有在白人和亞裔都投反對票的時候,議員A才會投反對票。
議員這一級的投票結果最終決定法案是否通過。要想通過一條議案,議員的投票數必須過半,也就是說,至少要有兩票。
這樣一個機製看上去非常公平。但現在讓我們假定政治家們都是些口是心非之徒,他們打算利用這個係統操控民意。接下來將要投票表決的有三個法案:平權法案,減稅法案和禁槍法案。政治家們出於自身利益的考慮,都希望通過前兩條法案而否決第三條法案。
由於這些法案的敏感性,政治家們已經可以準確地預測各個選民在投票時的表現。下表格就是他們的預測(1代表投讚成票,0代表投反對票):
|
|
白人 |
印第安人 |
亞裔 |
非裔 |
拉美裔 |
|
平權法案 |
1 |
0 |
0 |
1 |
0 |
|
減稅法案 |
1 |
1 |
1 |
0 |
0 |
|
禁槍法案 |
0 |
1 |
1 |
0 |
1 |
如果看選民的絕對票數,我們知道最後被通過的應該是減稅(3票)和禁槍法案(3票),而平權法案(2票)通不過。不過由於實行的是代議製,政治家們便有了可乘之機。他們隻是略施了些手腕,就讓最後的投票結果倒了過來:平權及減稅法案被通過,而禁槍法案被否決。
議員的投票應該綜合所代表選民的投票結果,他們不能自作主張地投與選民投票結果相悖的票。既然如此,他們是怎樣做到改變投票結果的呢?很簡單,三個議員看到白人和非裔的政治製度與自己的利益相同,於是都聲稱自己將代表這兩個選民的利益。這樣,他們就都可以為平權法案投讚成票而為禁槍法案投否決票了。
但如果忽視其他族裔的利益,減稅法案就通不過。於是三名議員又分別各增加了一個所代表的選民(隻能增加一個,再多禁槍法案就會被通過):
A說,除了白人和非裔,我還代表印第安人。根據我所代表的選民的投票結果,我被授權對平權法案和減稅法案投讚成票。
B說,除了白人和非裔,我還代表亞裔。根據我所代表的選民的投票結果,我被授權對平權法案和減稅法案投讚成票。
C說,除了白人和非裔,我還代表拉美裔。根據我所代表的選民的投票結果,我被授權對平權法案投讚成票。
最終投票結果:平權法案三票通過,減稅法案兩票通過,禁槍法案零票被否決。
雖然政治製度不是這麽玩的,然而神經網絡就是這麽玩的。整個投票的機製可以用下麵這個圖來表示:
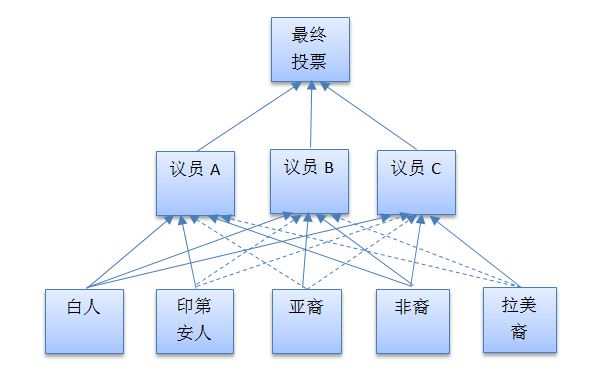
在這個兩級投票係統中,個體的投票不能直接決定議案的通過與否,卻可以左右代表他們的議員的投票。圖中,每個個體的投票被送往所有的議員,隻是有的議員代表他們的利益(用實線表示),有的議員不代表他們的利益(用虛線表示)。
在上圖中,隻有通過實線送至議員的投票才有效。舉例來說,指向議員C的有三根實線,分別來自白人,非裔和拉美裔。因此隻有這三個人的投票才會對C的投票產生影響。
我們也可以換一種方式來表述這個問題:讓個體選民的投票對每位議員都有效,隻不過給他們的投票加上權重。
怎樣加權重呢?很簡單:假如你是我所代表的族裔,你對我影響的權重就是1,假如你不是我所代表的族裔,你對我影響的權重就是0。也就是說,上圖中實線的權重都是1,而虛線的權重都是0。
下表便是本例中議員A、B、C對選民所加的不同權重:
|
|
白人 |
印第安人 |
亞裔 |
非裔 |
拉美裔 |
|
議員A |
1 |
1 |
0 |
1 |
0 |
|
議員B |
1 |
0 |
1 |
1 |
0 |
|
議員C |
1 |
0 |
0 |
1 |
1 |
權重是1的,你投一票我這兒就給你數一票。權重是0的,你投不投票我這兒都數0票。
再做一個換湯不換藥的修正:議員隻有在自己所代表選民的讚成票數達到半數以上時才能投讚成票。在這個例子中,議員A、B、C都隻代表三個選民,因而促使他們投讚成票的票數為2。給這個數字取個新名字:閾值。
於是偽民主製度便演化成了下麵的數學問題:每個議員在投票時,不需再看自己到底代表了誰。他/她隻需將所有選民的投票結果乘以其權重後相加,然後將總和與閾值比較,假如達到或大於閾值,就投讚成票,反之投反對票。
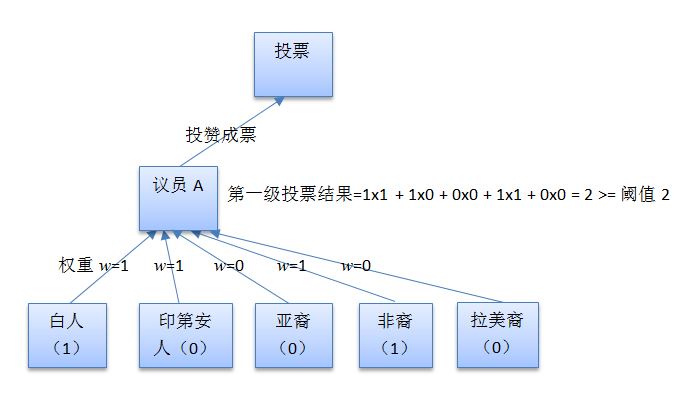
上圖便是議員A在對平權法案表決時投票的全過程示意圖。
假如能耐著性子讀到這裏,您就已經理解到神經網絡的精髓了。其實神經網絡並非深奧無比,其基本思路就是上麵這個偽民主代議製的投票過程。
隻不過,真正的神經網絡,在其最底層絕不會隻有五個投票的選民,一般也不會隻有一級代議的議員。現在流行的神經網絡一般有七級以上。為了與一般隻有兩、三級的神經網絡相區別,這類網絡往往被賦予“深度學習神經網絡”等神聖的名稱。
我們很快會看到,這樣一個多級投票機製是怎樣被用來解決生活中的實際問題的。
大家一定對手寫漢字輸入不陌生。在電話上刷刷寫上幾筆,對應的印刷體就會被調出來。電腦認識漢字,甚至還認識俺寫的那些歪歪斜斜的漢字!
其實隻要您懂得上麵的偽代議製投票原理,理解漢字識別就不是什麽難題了。
假設我們要教電腦識別阿拉伯數字“5” 。要想做這件事,首先我們要準備幾個手寫體的5和幾個其他數字。
第一步,把這些手寫體圖像量化,變為16x16的點陣。筆劃經過地方的值為1(讚成票),反之為0(反對票)。
第二步,建立多級代議製度,每一級都由一定數量的議員組成,這些議員都會收集前一級選民/議員的投票結果,把結果乘以權重後加起來,和閾值比較,然後根據比較結果決定自己投讚成票還是反對票。越往上議員越少,最高一級議員的投票直接決定議案通過與否。
第三步,把準備好的手寫體樣本送入投票係統,像議員操縱投票結果那樣要求係統在看到手寫體“5”時通過法案,而看到其他數字時否決法案。
人的腦子轉得過來嗎?當最底層選民的人數為五時,做做手腳是很容易的;然而,當這個數字變為16x16=256,需要表決的法案成百上千時(其實就是各種手寫體數字的變種),人們應該怎樣選擇各級的權重以及閾值使這個網絡輸出我們希望得到的結果呢?
我們可以一個一個地試呀!先為每個選民/議員隨機地選擇一個權重和閾值,然後看看能否達到我們希望的結果。如果不行,就調整一些權重和閾值再試,如果還不行,就再換……
熟悉嗎?蠻力搜索!用人腦去操縱民意隻能在很小的規模上進行。可一但用上電腦的蠻力,能夠操縱的規模就大多了。尤其是在電腦的計算能力日新月異的今天,計算成千上萬個輸入、七層以上的神經網絡已經不是難題了。當然,真正神經網絡的計算並非完全靠蠻力,但就像前麵計算圍棋問題一樣:那其實是一種優化後的蠻力,電腦的蠻力精神依舊在這裏被發揚光大。
需要說明的是,真正神經網絡的權重和閾值可以任意設置:它們不必局限於0、1或者正整數,可以是小數、負數。在做權重相加時一般也不會隻做簡單的線性相加,而是要引入更為複雜的算法。不過基本概念仍然不變。
那麽神經網絡為什麽一定得搭那麽多層,使計算變得複雜無比呢?少搭幾層省下計算時需要的電量,不但省事,而且還綠色環保,不是更好嗎?
不行,因為那樣是解決不了問題的。
我們前麵將神經網絡比喻為偽民主代議製。想想政治家在想要隱蔽地達到自己的目的時會怎麽做吧。當然是先把水攪渾,把問題搞得複雜無比,然後說,你們都玩不轉了吧,現在我來定一套非常公平的投票方案吧,大家一人一票,然後一級一級地代議,最後得出一個結論,公平而又合理。
於是大家按照政治家們定出的規則投票,得到的結果正是政治家們預先設定好的。
政治家們發明這麽多層的代議,就在於他們可以根據這個係統隨便操控民意,他們想通過這個法案就通過,想否決那個法案就否決,想全部通過或否決所有的法案也是做得到的。要達到這些目的,他們唯一需要做的事,便是調整係統中的權重和閾值。選民們被瞞天過海,還以為自己的投票得到了公正合理的計數。
科學家們發明了神經網絡,就在於這個網絡可以任意操縱評估結果。你把一張人臉照片送入係統,是可以通過操控權重和閾值使係統輸出“這是人臉”的結果的。你再把另一張人臉照片送入係統,同樣可以通過操控權重和閾值讓係統在看到這兩張照片的任何一張時都輸出“這是人臉”的結果。現在重複上述步驟,把各類人臉、貓臉、狗臉、狐狸臉的照片都往係統裏送,並讓係統在看到人臉照片時最終投讚成票,看到其他照片時投反對票。
當我們使用了足夠多的照片,對整個係統的參數進行了無數次微小的調整之後,奇跡便會出現:此時,即使拿來一張係統從未見過的人臉照片,它也會輸出“這是人臉”的答案。
神經網絡會“學習”了,能夠識別沒有見過的物體了!
然而如果我們仔細想想上述過程,就會明白其中的機理:這張新照片一定是和曾被用來訓練係統的某一張或幾張照片有著某種相似性,因而在投票時產生了類似的投票分布,所以才會最後輸出我們希望看到的結果。
神經網絡的最基本的要求,就是必須用海量的樣本來訓練它。
因為,唯有如此,才能提高新照片與某(幾)張樣本照片有較高相似度的可能性(樣本照片都會輸出人所希望的結果),從而產生類似的投票結果,完成“學習”的過程。
然而,再完美的訓練樣本都會有意外。即使學習了數十億張的人臉照片後,一定會有一些新照片並不與任何樣本照片產生足夠的相似度。這就是迄今為止,所有人臉識別係統都無法做到百分之百識別率的原因。
讓我們從反麵來理解這個問題。前麵說過,現代神經網絡一般都有七級以上的“代議”。把係統弄得這麽複雜,就在於科學家們可以隨意操控評估結果:他們可以讓各種類型的人臉——哭的、笑的、愁的、鬱悶的、皺紋斑斑的——在評估時都投讚成票。
但是,科學家們絕對有能力——雖然他們從來不這麽做———把神經網絡訓練成將人臉與垃圾桶不分彼此,將青蛙與汽車輪胎相提並論,將天上的星星和少女臉上的青春痘混為一談的係統。隻要人願意,神經網絡是可以通過“學習”實現上述功能的。
因為,神經網絡的實質就是:它的代議是萬能的,任何兩(多)種輸入,不管它們是不是互為關聯,都可以通過操控各層的參數產生同一評估結果。神經網絡既弄不懂,也不會關心這些輸入之間有沒有邏輯上的聯係。神經網絡如何學習,就看人怎樣訓練它。
通過以上描述,我們可以歸納出神經網絡的三個特征:1)必須有足夠多的層數讓操縱評估結果成為可能。2)必須用足夠多的樣本來訓練網絡,讓網絡產生人所希望的評估。3)實際使用時,輸入網絡的數據不能和這些樣本相去太遠。
仍以人臉識別為例。假如我們用各種臉型的照片來訓練網絡:圓的、方的、瓜子的、倒三角的……這時如果我們拿來一張半圓半方臉的照片,網絡雖然沒見過,卻很有可能會識別出這是人臉,因為此時,那些對圓臉敏感的權重和對方臉敏感的權重會同時作用,在以後的代議中,這些權重會被疊加而最終輸出“是人臉”這一結論。
然而,假如此時給網絡看一張大胡子照片,它就不知所措了,因為樣本裏沒有一張長胡子的照片。此時解決問題的唯一辦法就是繼續找來各種有胡子的人臉照片——長的、短的、山羊的、絡腮的——來訓練網絡,以希望將來再次遇到長胡子的人臉照片時,會和這些新樣本類似。
迄今為止多數人工智能產品都是基於上述原理而搭建的。雖然有各類讓人眼花繚亂的變種,但萬變不離其宗,因而也就保留了這些先天不足。想想我們熟悉的產品:物體識別、語音識別、機器翻譯……都無一例外地打著這個烙印。近些年來發生在人工領域裏的飛速進展,與其說是機器變得更聰明了,更會學習了,倒不如說是由於計算能力的增強和信息量的倍增,而使得操控評估結果變得更為可能和更有現實意義了。
神經網絡其實更像一個沒有思想的木偶:雖然它能在台上做出各種活靈活現、栩栩如生的表演,然而它自身並不知道自己所做的動作包含著怎樣的意義,牽掛在它身上的一條條操縱線才是真正藏而不露的玄機。
話題終於可以繞回到圍棋之上來了。用神經網絡下棋,可能嗎?
我們可以搭建一個類似人臉識別那樣的多級評估結構。圍棋盤的輸入為19x19的點陣,每個點有3個狀態(白子、黑子、無子),總信息量比普通低清晰度照片還少好幾個量級!然後,我們可以把名家對局的棋譜輸入網絡,然後通過調整權重和閾值,使係統在看到已知棋局時都走出正確的落子。問題的關鍵就在於,這樣訓練出來的網絡能否在看到未知棋局時也作出正確的判斷。
直覺告訴我們這樣做是行不通的,因為兩個幾乎一模一樣的棋局,很可能就因為某個地方多了或少了一個子,接下來的下法就完全不同。比如說有一片黑棋,它中間沒有眼,有一個眼或兩個眼,對於下一步落子的意義是完全不一樣的。
那麽,有沒有辦法把不同的算法結合起來,取長補短,來打造一個強大無比的電腦圍棋鬥士呢?
待續
階梯講師原創作品•謝謝閱讀
更多我的博客文章>>>