如何成為一名數據科學家?
1. 業務知識
2. 數理統計和數據分析
3. 計算機相關知識
3.1 數據處理與收集(ETL?)
3.2 機器學習和數據挖掘
這幾方麵完全是自己的一個猜測,懇請大牛們不惜賜教!
28 個回答

恰好我馬上啟程到Twitter的data science team,而且恰巧懂一點點統計和住在舊金山,所以衝動地沒有邀請就厚臉回答了:D
我認為有幾個大方麵
1)學好python。
現在幾乎所以公司的數據都可以api給你,而python的數據處理能力強大且方便。加之在machine learning的很多算法上,python也獨俏一方。另外,它的簡明方便迅速迭代開發,15分鍾寫完個算法就可以看效果了。
除此之外,py還有點酷酷的感覺。任何程序拿matlab和c++都是可以寫的,不過我真沒認識過哪個d願意自己把自己扔那個不酷的框框裏:D
對不規則輸入的處理也給python一個巨大的優勢。通常來說,在我現在日常的工作裏,所有的數據都是以純文本但是非格式的形式存儲的(raw text, unstructured data)。問題在於,這些文本不可以直接當作各種算法的輸入,你需要
- 分詞,分句
- 提取特征
- 整理缺失數據
- 除掉異類(outlier)
簡而言之,對於數據科學麵臨的挑戰,python可以讓你短平快地解決手中的問題,而不是擔心太多實現細節。
2)學好統計學習
略拗口。統計學習的概念就是“統計機器學習方法”。
統計和計算機科學前幾十年互相平行著,互相造出了對方造出的一係列工具,算法。但是直到最近人們開始注意到,計算機科學家所謂的機器學習其實就是統計裏麵的prediction而已。因此這兩個學科又開始重新融合。
為什麽統計學習很重要?
因為,純粹的機器學習講究算法預測能力和實現,但是統計一直就強調“可解釋性”。比如說,針對今天微博股票發行就上升20%,你把你的兩個預測股票上漲還是下跌的model套在新浪的例子上,然後給你的上司看。
Model-1有99%的預測能力,也就是99%的情況下它預測對,但是Model-2有95%,不過它有例外的一個附加屬性——可以告訴你為什麽這個股票上漲或者下跌。
試問,你的上司會先哪個?問問你自己會選哪個?
顯然是後者。因為前者雖然有很強的預測力(機器學習),但是沒有解釋能力(統計解釋)。
而作為一個數據科學家,80%的時間你是需要跟客戶,團隊或者上司解釋為什麽A可行B不可行。如果你告訴他們,“我現在的神經網絡就是能有那麽好的預測力可是我根本就沒法解釋上來”,那麽,沒有人會願意相信你。
具體一些,怎麽樣學習統計學習?
- 先學好基本的概率學。如果大學裏的還給老師了(跟我一樣),那麽可以從MIT的概率論教材【1】入手。從第1章到第9章看完並做完所有的習題。(p.s.麵試Twitter的時候被問到一個拿球後驗概率的問題,從這本書上抓來的)。
- 了解基本的統計檢驗及它們的假設,什麽時候可以用到它們。
- 快速了解統計學習有哪些術語,用來做什麽目的,讀這本【5】。
- 學習基本的統計思想。有frequentist的統計,也有bayesian的統計。前者的代表作有【2】,後者看【3】。前者是統計學習的聖書,偏frequentist,後者是pattern recognition的聖書,幾乎從純bayesian的角度來講。注意,【2】有免費版,作者把它全放在了網上。而且有一個簡易版,如果感覺力不從心直接看【2】,那麽可以先從它的簡易版開始看。簡易版【4】是作者在coursera上開課用的大眾教材,簡單不少(不過仍然有很多閃光點,通俗易懂)。對於【3】,一開始很難直接啃下來,但是啃下來會受益匪淺。
讀完以上的書是個長期過程。但是大概讀了一遍之後,我個人覺得是非常值得的。如果你隻是知道怎麽用一些軟件包,那麽你一定成不了一個合格的data scientist。因為隻要問題稍加變化,你就不知道怎麽解決了。
如果你感覺自己是一個二吊子數據科學家(我也是)那麽問一下下麵幾個問題,如果有2個答不上來,那麽你就跟我一樣,真的還是二吊子而已,繼續學習吧。
- 為什麽在神經網絡裏麵feature需要standardize而不是直接扔進去
- 對Random Forest需要做Cross-Validatation來避免overfitting嗎?
- 用naive-bayesian來做bagging,是不是一個不好的選擇?為什麽?
- 在用ensembe方法的時候,特別是Gradient Boosting Tree的時候,我需要把樹的結構變得更複雜(high variance, low bias)還是更簡單(low variance, high bias)呢?為什麽?
說個題外話,我很欣賞一個叫Jiro的壽司店,它的店長在(東京?)一個最不起眼的地鐵站開了一家全世界最貴的餐館,預訂要提前3個月。怎麽做到的?70年如一日練習如何做壽司。70年!除了喪娶之外的假期,店長每天必到,8個小時工作以外繼續練習壽司做法。
其實學數據科學也一樣,沉下心來,練習匠藝。
3)學習數據處理
這一步不必獨立於2)來進行。顯然,你在讀這些書的時候會開始碰到各種算法,而且這裏的書裏也會提到各種數據。但是這個年代最不值錢的就是數據了(拜托,為什麽還要用80年代的“加州房價數據”?),值錢的是數據分析過後提供給決策的價值。那麽與其糾結在這麽悲劇的80年代數據集上,為什麽不自己搜集一些呢?
- 開始寫一個小程序,用API爬下Twitter上隨機的tweets(或者weibo吧。。。)
- 對這些tweets的text進行分詞,處理噪音(比如廣告)
- 用一些現成的label作為label,比如tweet裏會有這條tweet被轉發了幾次
- 嚐試寫一個算法,來預測tweet會被轉發幾次
- 在未見的數據集上進行測試
4)變成全能工程師(full stack engineer)
在公司環境下,作為一個新入職的新手,你不可能有優待讓你在需要寫一個數據可視化的時候,找到一個同事來給你做。需要寫把數據存到數據庫的時候,找另一個同事來給你做。
況且即使你有這個條件,這樣頻繁切換上下文會浪費更多時間。比如你讓同事早上給你塞一下數據到數據庫,但是下午他才給你做好。或者你需要很長時間給他解釋,邏輯是什麽,存的方式是什麽。
最好的變法,是把你自己武裝成一個全能工作師。你不需要成為各方麵的專家,但是你一定需要各方麵都了解一點,查一下文檔可以上手就用。
- 會使用NoSQL。尤其是MongoDB
- 學會基本的visualization,會用基礎的html和javascript,知道d3【6】這個可視化庫,以及highchart【7】
- 學習基本的算法和算法分析,知道如何分析算法複雜度。平均複雜度,最壞複雜度。每次寫完一個程序,自己預計需要的時間(用算法分析來預測)。推薦普林斯頓的算法課【8】(注意,可以從算法1開始,它有兩個版本)
- 寫一個基礎的服務器,用flask【9】的基本模板寫一個可以讓你做可視化分析的backbone。
- 學習使用一個順手的IDE,VIM, pycharm都可以。
4)讀,讀,讀!
除了閉門造車,你還需要知道其它數據科學家在做些啥。湧現的各種新的技術,新的想法和新的人,你都需要跟他們交流,擴大知識麵,以便更好應對新的工作挑戰。
通常,非常厲害的數據科學家都會把自己的blog放到網上供大家參觀膜拜。我推薦一些我常看的。另外,學術圈裏也有很多厲害的數據科學家,不必怕看論文,看了幾篇之後,你就會覺得:哈!我也能想到這個!
讀blog的一個好處是,如果你跟他們交流甚歡,甚至於你可以從他們那裏要一個實習來做!
betaworks首席數據科學家,Gilad Lotan的博客,我從他這裏要的intern :D Gilad Lotan
Ed Chi,六年本科碩士博士畢業的神人,google data science http://edchi.blogspot.com/
Hilary Mason,bitly首席科學家,紐約地區人盡皆知的數據科學家:hilarymason.com
在它們這裏看夠了之後,你會發現還有很多值得看的blog(他們會在文章裏麵引用其它文章的內容),這樣滾雪球似的,你可以有夠多的東西早上上班的路上讀了:)
5)要不要上個研究生課程?
先說我上的網絡課程:
Coursera.org
https://www.coursera.org/course/machlearning
前者就不說了,人人都知道。後者我則更喜歡,因為教得更廣闊,上課的教授也是世界一流的機器學習學者,而且經常會有一些很妙的點出來,促進思考。
對於是不是非要去上個研究生(尤其要不要到美國上),我覺得不是特別有必要。如果你收到了幾個著名大學數據科學方向的錄取,那開開心心地來,你會學到不少東西。但是如果沒有的話,也不必糾結。我曾有幸上過或者旁聽過美國這裏一些頂級名校的課程,我感覺它的作用仍然是把你領進門,以及給你一個能跟世界上最聰明的人一個交流機會(我指那些教授)。除此之外,修行都是回家在寢室進行的。然而現在世界上最好的課程都擺在你的麵前,為什麽還要舍近求遠呢。
總結一下吧
我很幸運地跟一些最好的數據科學家交流共事過,從他們的經曆看和做事風格來看,真正的共性是
他們都很聰明——你也可以
他們都很喜歡自己做的東西——如果你不喜歡應該也不會看這個問題
他們都很能靜下心來學東西——如果足夠努力你也可以
【1】Introduction to Probability and Statistics
【2】Hastie, Trevor, et al. The elements of statistical learning. Vol. 2. No. 1. New York: Springer, 2009. 免費版
【3】Bishop, Christopher M. Pattern recognition and machine learning. Vol. 1. New York: springer, 2006.
【4】Introduction to Statistical Learning 免費版
【5】Wasserman, Larry. All of statistics: a concise course in statistical inference. Springer, 2004.
【6】http://d3js.org/
【7】http://www.highcharts.com/
【8】Coursera.org
【9】http://flask.pocoo.org/

-
版本更新,2014年5月14日更新一些內容。
-
如果展開講,這個問題可以寫一篇綜述了。最近剛好有空,打算認真寫寫。
僅僅在幾年前,數據科學家還不是一個正式確定的職業,然而一眨眼的工夫,這個職業就已經被譽為“今後十年IT行業最重要的人才”了。
一、數據科學家的起源
"數據科學"(DataScience)起初叫"datalogy "。最初在1966年由Peter Naur提出,用來代替"計算機科學"(丹麥人,2005年圖靈獎得主,丹麥的計算機學會的正式名稱就叫Danish Society of Datalogy,他是這個學會的第一任主席。Algol 60是許多後來的程序設計語言,包括今天那些必不可少的軟件工程工具的原型。圖靈獎被認為是“計算科學界的諾貝爾獎”。)
1996年,International Federation of Classification Societies (IFCS)國際會議召開。數據科學一詞首次出現在會議(Data Science, classification, and related methods)標題裏。
1998年,C.F. Jeff Wu做出題為“統計學=數據科學嗎? 的演講,建議統計改名數據的科學統計數據的科學家。 (吳教授於1987年獲得COPSS獎,2000年在台灣被選為中研院院士,2004年作為第一位統計學者當選美國國家工程院院士,也是第一位華人統計學者獲此殊榮。)
2002年,國際科學理事會:數據委員會科學和技術(CODATA)開始出版數據科學雜誌。
2003年,美國哥倫比亞大學開始發布數據科學雜誌,主要內容涵蓋統計方法和定量研究中的應用。
2005年,美國國家科學委員會發表了"Long-lived Digital Data Collections: Enabling Research and Education in the 21st Century",其中給出數據科學家的定義:
"the information and computer scientists, database and software and programmers, disciplinary experts, curators and expert annotators, librarians, archivists, and others, who are crucial to the successful management of a digital data collection"
信息科學與計算機科學家,數據庫和軟件工程師,領域專家,策展人和標注專家,圖書管理員,檔案員等數字數據管理收集者都以可成為數據科學家。它們主要任務是:"進行富有創造性的查詢和分析。"
2012年,O'Reilly媒體的創始人 Tim O'Reilly 列出了世界上排名前7位的數據科學家。
- Larry Page,穀歌CEO。
- Jeff Hammerbacher,Cloudera的首席科學家和DJ Patil,Greylock風險投資公司企業家。
- Sebastian Thrun,斯坦福大學教授和Peter Norvig,穀歌數據科學家。
- Elizabeth Warren,Massachusetts州美國參議院候選人。
- Todd Park,人類健康服務部門首席技術官。
- Sandy Pentland,麻省理工學院教授。
- Hod Lipson and Michael Schmidt,康奈爾大學計算機科學家。
具體有時間再補充,感興趣的朋友可以Google Scholar一下他們的文獻。
關於數據科學家的更多討論:
你能列出十個著名的女性數據科學家嗎?Can you name 10 famous data scientist women?
誰是最富有的數據科學家?Who are the wealthiest data scientists?
請列出對大數據最具有影響力的20個人?Who Are The Top 20 Influencers in Big Data?
二、數據科學家的定義
數據科學(Data Science)是從數據中提取知識的研究,關鍵是科學。數據科學集成了多種領域的不同元素,包括信號處理,數學,概率模型技術和理論,機器學習,計算機編程,統計學,數據工程,模式識別和學習,可視化,不確定性建模,數據倉庫,以及從數據中析取規律和產品的高性能計算。數據科學並不局限於大數據,但是數據量的擴大誠然使得數據科學的地位越發重要。
數據科學的從業者被稱為數據科學家。數據科學家通過精深的專業知識在某些科學學科解決複雜的數據問題。不遠的將來,數據科學家們需要精通一門、兩門甚至多門學科,同時使用數學,統計學和計算機科學的生產要素展開工作。所以數據科學家就如同一個team。
曾經投資過Facebook,LinkedIn的格雷洛克風險投資公司把數據科學家描述成“能夠管理和洞察數據的人”。在IBM的網站上,數據科學家的角色被形容成“一半分析師,一半藝術家”。他們代表了商業或數據分析這個角色的一個進化。
for example – a data scientist will most likely explore and examine data from multiple disparate sources. The data scientist will sift through all incoming data with the goal of discovering a previously hidden insight, which in turn can provide a competitive advantage or address a pressing business problem. A data scientist does not simply collect and report on data, but also looks at it from many angles, determines what it means, then recommends ways to apply the data.
- Anjul Bhambhri,IBM的大數據產品副總裁。
- Jonathan Goldman,LinkedIn數據科學家。
2006年的6月份進入商務社交網站LinkedIn,當時LinkedIn隻有不到800萬用戶。高德曼在之後的研究中創造出新的模型,利用數據預測注冊用戶的人際網絡。具體來講,他以用戶在LinkedIn的個人資料,來找到和這些信息最匹配的三個人,並以推薦的形式顯示在用戶的使用頁麵上——這也就是我們熟悉的"你可能認識的人(People you may know)"。這個小小的功能讓LinkedIn增加了數百萬的新的頁麵點擊量(數據挖掘的應用典型之一推薦係統)。
- John Rauser, 亞馬遜大數據科學家。
數據科學家是工程師和統計學家的結合體。從事這個職位要求極強的駕馭和管理海量數據的能力;同時也需要有像統計學家一樣萃取、分析數據價值的本事,二者缺一不可。
- Steven Hillion, EMC Greenplum數據分析副總裁。
數據科學家是具有極強分析能力和對統計和數學有很深研究的數據工程師。他們能從商業信息等其他複雜且海量的數據庫中洞察新趨勢。
- Monica Rogati, LinkedIn資深數據科學家。
所有的科學家都是數據學家,因為他們整天都在和海量數據打交道。在我眼中,數據學家是一半黑客加一半分析師。他們通過數據建立看待事物的新維度。數據學家必須能夠用一隻眼睛發現新世界,用另一隻眼睛質疑自己的發現。
- Daniel Tunkelang,LinkedIn首席數據科學家。
我是bitly 首席科學家Hilary Mason的忠實崇拜者。關於這個新概念的定義我也想引用她的說法:數據科學家是能夠利用各種信息獲取方式、統計學原理和機器的學習能力對其掌握的數據進行收集、去噪、分析並解讀的角色。
- Michael Rappa,北卡羅萊納州立大學教授。
盡管數據科學家這個名稱最近才開始在矽穀出現,但這個新職業的產生卻是基於人類上百年對數據分析的不斷積累和衍生。和數據科學家最接近的職業應該是統計學家,隻不過統計學家是一個成熟的定義且服務領域基本局限於政府和學界。數據科學家把統計學的精髓帶到了更多的行業和領域。
- 林仕鼎,百度大數據首席架構師。
如果從廣義的角度講,從事數據處理、加工、分析等工作的數據科學家、數據架構師和數據工程師都可以籠統地稱為數據科學家;而從狹義的角度講,那些具有數據分析能力,精通各類算法,直接處理數據的人員才可以稱為數據科學家。
最後引用Thomas H. Davenport(埃森哲戰略變革研究院主任) 和 D.J. Patil(美國科學促進會科學與技術政策研究員,為美國國防部服務)的話來總結數據科學家需要具備的能力:
- 數據科學家傾向於用探索數據的方式來看待周圍的世界。(好奇心)
- 把大量散亂的數據變成結構化的可供分析的數據,還要找出豐富的數據源,整合其他可能不完整的數據源,並清理成結果數據集。(問題分體整理能力)
- 新的競爭環境中,挑戰不斷地變化,新數據不斷地流入,數據科學家需要幫助決策者穿梭於各種分析,從臨時數據分析到持續的數據交互分析。(快速學習能力)
- 數據科學家會遇到技術瓶頸,但他們能夠找到新穎的解決方案。(問題轉化能力)
- 當他們有所發現,便交流他們的發現,建議新的業務方向。(業務精通)
- 他們很有創造力的展示視覺化的信息,也讓找到的模式清晰而有說服力。(表現溝通能力)
- 他們會把蘊含在數據中的規律建議給Boss,從而影響產品,流程和決策。(決策力)
三、數據科學家所需硬件技能
《數據之美 Beautiful Data》的作者Jeff Hammerbacher在書中提到,對於 Facebook 的數據科學家“我們發現傳統的頭銜如商業分析師、統計學家、工程師和研究科學家都不能確切地定義我們團隊的角色。該角色的工作是變化多樣的:
在任意給定的一天,團隊的一個成員可以用 Python 實現一個多階段的處理管道流、設計假設檢驗、用工具R在數據樣本上執行回歸測試、在 Hadoop 上為數據密集型產品或服務設計和實現算法,或者把我們分析的結果以清晰簡潔的方式展示給企業的其他成員。為了掌握完成這多方麵任務需要的技術,我們創造了數據科學家這個角色。”
(1) 計算機科學
一般來說,數據科學家大多要求具備編程、計算機科學相關的專業背景。簡單來說,就是對處理大數據所必需的Hadoop、Mahout等大規模並行處理技術與機器學習相關的技能。
(2) 數學、統計、數據挖掘等
除了數學、統計方麵的素養之外,還需要具備使用SPSS、SAS等主流統計分析軟件的技能。其中,麵向統計分析的開源編程語言及其運行環境“R”最近備受矚目。R的強項不僅在於其包含了豐富的統計分析庫,而且具備將結果進行可視化的高品質圖表生成功能,並可以通過簡單的命令來運行。此外,它還具備稱為CRAN(The Comprehensive R Archive Network)的包擴展機製,通過導入擴展包就可以使用標準狀態下所不支持的函數和數據集。R語言雖然功能強大,但是學習曲線較為陡峭,個人建議從python入手,擁有豐富的statistical libraries,NumPy ,SciPy.org ,Python Data Analysis Library,matplotlib: python plotting。
(3) 數據可視化(Visualization)
信息的質量很大程度上依賴於其表達方式。對數字羅列所組成的數據中所包含的意義進行分析,開發Web原型,使用外部API將圖表、地圖、Dashboard等其他服務統一起來,從而使分析結果可視化,這是對於數據科學家來說十分重要的技能之一。
(4) 跨界為王
麥肯錫認為未來需要更多的“translators”,能夠在IT技術,數據分析和商業決策之間架起一座橋梁的複合型人才是最被人需要的。”translators“可以驅動整個數據分析戰略的設計和執行,同時連接的IT ,數據分析和業務部門的團隊。如果缺少“translators“,即使擁有高端的數據分析策略和工具方法也是於事無補的。
The data strategists’combination of IT knowledge and experience making business decisions makes them well suited to define the data requirements for high-value business analytics. Data scientists combine deep analytics expertise with IT know-how to develop sophisticated models and algorithms. Analytic consultants combine practical business knowledge with analytics experience to zero in on high-impact opportunities for analytics.
天才的”translators“非常罕見。但是大家可以各敬其職(三個臭皮匠臭死諸葛亮),數據戰略家可以使用IT知識和經驗來製定商業決策,數據科學家可以結合對專業知識的深入理解使用IT技術開發複雜的模型和算法,分析顧問可以結合實際的業務知識與分析經驗聚焦下一個行業爆點。
推薦關注:https://www.facebook.com/data四、數據科學家的培養
位於伊利諾伊州芝加哥郊外埃文斯頓市的美國名牌私立大學——西北大學(Northwestern University),就是其中之一。西北大學決定從2012年9月起在其工程學院下成立一個主攻大數據分析課程的分析學研究生院,並開始了招生工作。西北大學對於成立該研究生院是這樣解釋的:“雖然隻要具備一些Hadoop和Cassandra的基本知識就很容易找到工作,但擁有深入知識的人才卻是十分缺乏的。”
此外,該研究生院的課程計劃以“傳授和指導將業務引向成功的技能,培養能夠領導項目團隊的優秀分析師”為目標,授課內容在數學、統計學的基礎上,融合了尖端計算機工程學和數據分析。課程預計將涵蓋分析領域中主要的三種數據分析方法:預測分析、描述分析(商業智能和數據挖掘)和規範分析(優化和模擬),具體內容如下。
(1) 秋學期
* 數據挖掘相關的統計方法(多元Logistic回歸分析、非線性回歸分析、判別分析等)
* 定量方法(時間軸分析、概率模型、優化)
* 決策分析(多目的決策分析、決策樹、影響圖、敏感性分析)
* 樹立競爭優勢的分析(通過項目和成功案例學習基本的分析理念)
(2) 冬學期
* 數據庫入門(數據模型、數據庫設計)
* 預測分析(時間軸分析、主成分分析、非參數回歸、統計流程控製)
* 數據管理(ETL(Extract、Transform、Load)、數據治理、管理責任、元數據)
* 優化與啟發(整數計劃法、非線性計劃法、局部探索法、超啟發(模擬退火、遺傳算法))
(3) 春學期
* 大數據分析(非結構化數據概念的學習、MapReduce技術、大數據分析方法)
* 數據挖掘(聚類(k-means法、分割法)、關聯性規則、因子分析、存活時間分析)
* 其他,以下任選兩門(社交網絡、文本分析、Web分析、財務分析、服務業中的分析、能源、健康醫療、供應鏈管理、綜合營銷溝通中的概率模型)
(4) 秋學期
* 風險分析與運營分析的計算機模擬
* 軟件層麵的分析學(組織層麵的分析課題、IT與業務用戶、變革管理、數據課題、結果的展現與傳達方法)
(EMC的在線課程:Data Science and Big Data Analytics Training,收費T_T,大家可以了解下學習路徑)
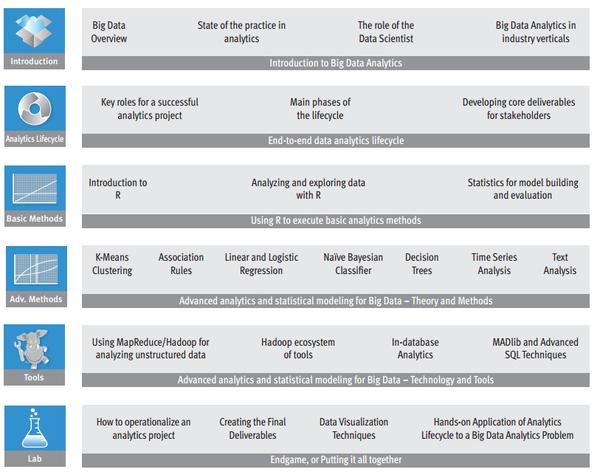 (EMC的在線課程:
(EMC的在線課程:(5)分享一些免費的課程
以下課程免費,講師都是領域的專家,需要提前報名,請注意開班的時間。
- Coursera.org:統計學。
- Coursera.org:機器學習。
- Coursera.org:數據分析的計算方法。
- Coursera.org:大數據。
- Coursera.org:數據科學導論。
- Coursera.org:數據分析。
- Statistical Thinking and Data Analysis:麻省理工學院的統計思維與數據分析課。概率抽樣,回歸,常見分布等。
- Data Mining | Sloan School of Management:麻省理工學院的數據挖掘課程,數據挖掘的知識以及機器學習算法。
- Rice University Data Visualization:萊斯大學的數據可視化,從統計學的角度分析信息可視化。
- Harvard University Introduction to Computing, Modeling, and Visualization: 哈佛大學,如何在數學計算與數據交互可視化之間架起橋梁。
- UC Berkeley Visualization:加州大學伯克利分校數據可視化。
- Data Literacy Course -- IAP:兩個MIT的數據研究生,如何分析處理可視化數據。
- Columbia University Applied Data Science:哥倫比亞大學,數據分析方法。需要一定的數據基礎。
- SML: Systems:加州大學伯克利分校,可擴展的機器學習方法。從硬件係統,並行化範式到MapReduce+Hadoop+BigTable,非常全麵係統。
五、數據科學家的前景
(EMC - Leading Cloud Computing, Big Data, and Trusted IT Solutions,關於數據科學家的研究)
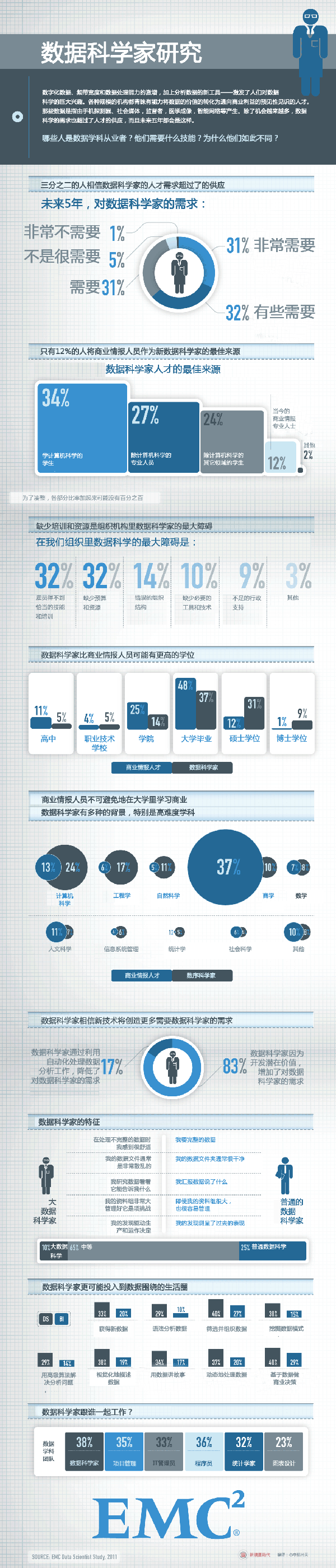 (
(Like the physical universe, the digital universe is large – by 2020 containing nearly as many digital bits as there are stars in the universe. It is doubling in size every two years, and by 2020 the digital universe – the data we create and copy annually – will reach 44 zettabytes, or 44 trillion gigabytes.
 Like the physical universe, the digital universe is large – by 2020 containing nearly as many digital bits as there are stars in the universe. It is doubling in size every two years, and by 2020 the digital universe – the data we create and copy annually – will reach 44 zettabytes, or 44 trillion gigabytes.
Like the physical universe, the digital universe is large – by 2020 containing nearly as many digital bits as there are stars in the universe. It is doubling in size every two years, and by 2020 the digital universe – the data we create and copy annually – will reach 44 zettabytes, or 44 trillion gigabytes.
EMC預測,按照目前的情況數字宇宙以每兩年一番的速度倍增,在2020年將到達44ZB(1ZB=1.1805916207174113e+21B)。EMC做出了5點比較大膽的預測。
- In 2013, while about 40% of the information in the digital universe required some type of data protection, less than 20% of the digital universe actually had these protections.
- Data from embedded systems, the signals from which are a major component of the Internet of Things, will grow from 2% of the digital universe in 2013 to 10% in 2020.
- In 2013, less than 20% of the data in the digital universe is “touched” by the cloud, either stored, perhaps temporarily, or processed in some way. By 2020, that percentage will double to 40%.
- Most of the digital universe is transient – unsaved Netflix or Hulu movie streams, or Xbox One gamer interactions, temporary routing information in networks, sensor signals discarded when no alarms go off, etc. – and it is getting more so. This is a good thing, because the world’s amount of available storage capacity (i.e., unused bytes) across all media types is growing slower than the digital universe. In 2013, the available storage capacity could hold just 33% of the digital universe. By 2020, it will be able to store less than 15%.
- In 2014, the digital universe will equal 1.7 megabytes a minute for every person on Earth.
Between 2013 and 2020 the division of the digital universe between mature and emerging markets (e.g., China) will switch – from 60% accounted for by mature markets to 60% of the data in the digital universe coming from emerging markets.
 Between 2013 and 2020 the division of the digital universe between mature and emerging markets (e.g., China) will switch – from 60% accounted for by mature markets to 60% of the data in the digital universe coming from emerging markets.
Between 2013 and 2020 the division of the digital universe between mature and emerging markets (e.g., China) will switch – from 60% accounted for by mature markets to 60% of the data in the digital universe coming from emerging markets.
EMC預測在2017年左右新興的市場將超越成熟市場,東亞國家是最具潛力的引爆點。(大家是不是有點小激動,前景一片光明)
六、結束語
推薦網站:
Data Science Central (數據科學中心,大牛雲集,資源豐富,討論者熱情,各種課程)
祝每一個DMer都挖掘到金礦和快樂:)
參考文獻:
[1].Data Scientists: The Definition of Sexy
[2].《大數據的衝擊》. 城田真琴. 野村綜合研究所創新開發部高級研究員、IT分析師,日本政府“智能雲計算研究會”智囊團成員
[3].麥肯錫. Big data: The next frontier for innovation, competition, and productivity
[4].EMC. Executive Summary: Data Growth, Business Opportunities, and the IT Imperatives
[5].EMC Greenplum's Steven Hillion on What Is a Data Scientist?
[6].LinkedIn's Monica Rogati On "What Is A Data Scientist?"
[7].IBM - What is a Data Scientist?
[8].Data Science and Prediction
[9].The key word in “Data Science” is not Data, it is Science
[10].Data Science: How do I become a data scientist?
[11].A Practical Intro to Data Science
[12].解碼數據科學家

現在很火的數據科學data science到底是什麽?你對做Data Scientist感興趣嗎?
數據科學家data scientist需要的三大核心技能:Data Hacking、Problem Solving and Communication
想成為數據科學家Data Scientist,需要申請讀什麽專業?
美國哪些公司招聘Data Scientist?看重數據科學家什麽方麵的背景?
數據科學家Data Scientist的職業發展前景如何?
推薦《說說Data Science的入門級工作》和《數據科學就業前景觀察分析》,歡迎來分享你的經驗和看法!
數據科學家Data Scientist能掙多少錢?
做數據科學家Data Scientist,碩士Master和博士PhD學位有啥區別?

本文來源:Medium 譯文創見
數據分析到底是什麽?很多人都在嘴邊討論它們,卻沒有幾個人真正見過它。這是當下科技行業最為火爆的職位,今天就讓我們走進 Twitter 的數據分析世界,看看科技公司對於一個數據分析師的要求是什麽?他們的實際工作內容究竟是哪些?
Robert Chang 在 Twitter 工作兩年了。根據他個人的工作經曆,Twitter 數據分析(以下簡稱為 DS)有了下麵三個層麵的變化:
1.機器學習已經在 Twitter 多個核心產品中扮演越來越重要的角色,而這之前完全是「機器學習」的禁區。最典型的例子就是「當你離開時」這個功能。當用戶離開頁麵或者電腦,去幹別的事情後再次返回頁麵,電腦會立刻給你推送出來某些由你關注的人所發出,而有可能被你錯過的「優質內容」。
2.開發工具越來越優秀了。整個團隊擺脫了對 Pig 的依賴,全新的數據管道是在 Scalding 中寫出來的。
3.從團隊組織上而言,Twitter 已經轉向了一個嵌入式的模型中。其中數據分析比以往更加緊密地與產品 / 工程團隊發生著聯係。
在 Twitter 的工作確實是令人興奮的,因為你能站在這個平台上,引領目前世界最前沿的數據科技,打造最具競爭力的優勢。而同時,人們對於大數據的渴望也一天比一天高。
Dan Ariely 曾經有一句話說得特別好:
「大數據其實有點兒像青少年的性。每一個人都興致勃勃地談論它,但是沒有任何一個人真的知道該怎麽做。每一個人都覺得身邊的人都在嚐試,為了不落人後,於是每個人都在外麵宣城自己也已經有『伴兒』了」
現如今,有太多的人在如何成為一名優秀稱職的數據分析師上表達著看法,給出自己的建議。Robert Chang 毫無疑問也是受益者。但是他回過頭來再想想大家的討論,會覺得人們往往更加側重於去談「技術」、「工具」、「技能組合」,而在 Chang 看來,那些東西確實很重要,但是讓新人們知道數據分析師每一天的生活到底是什麽樣子的,具體的工作內容都是什麽,這也非常重要。
於是,Chang 憑借著自己在 Twitter 工作兩年的經曆,以自己作為例子,首次打開 Twitter 數據分析師這扇神秘的大門。
A 型數據分析師 VS B 型數據分析師
Chang 在沒來 Twitter 之前,總覺得數據分析師一定是在任何領域都能看堪稱「獨角獸」,不管是數據還是數學專業,都是頂尖人才。除了技術上很牛之外,書麵寫作和口頭交流的能力也會特別強。更重要的是他們能夠分清楚當下工作的輕重緩急,領導和管理一個項目團隊。是啊,如今本身就是以數據為主導的文化,作為「數據分析師」,當然要給這個文化注入靈魂與活力啊!
在 Chang 加入 Twitter 的幾個月後,他逐漸意識到:符合上述形容的「獨角獸」確實存在,但是對於大部分人來說,上述的要求未免有點兒太不切實際了。人們沒有辦法做到麵麵俱到。後來,Chang 通過 Quora 中的一篇回答,更深刻地理解了數據分析師的角色。在那篇文章中,數據分析師分成了兩種類型:
A 型數據分析師: 他們主要負責「分析」。他們最關心數據背後的意義,往往使用統計等方式探知真相。其實他們的工作有點兒像「統計學家」,但是不一樣的地方是,統計學專業涉及的內容他們統統掌握,但是他們還會一些統計學課本裏麵壓根不曾出現的內容:比如數據清洗,如何處理超大數據組,數據視覺化,有關數據層麵的報告撰寫等等。
B 型數據分析師:B 型負責「建造」。他們跟前一種分析師有著相似的統計學背景,但他們同時還是非常牛叉的程序員,又或者是訓練有素的軟件工程師。B 型數據分析師往往感興趣於「如何利用數據來生產」。他們建立一些能夠與用戶互動的模型,往往以「推薦 / 推送」的形式出現,比如「你也許會認識的人」,「廣告」,「電影」,「搜索結果」等等功能。
Chang 看到這樣清楚的劃分,非常後悔如果早幾年有這麽清楚的概念認識該多好啊。這樣他就能夠有選擇性的發力,擇其一方向來繼續發展。這是數據分析師職場規劃首先要考慮的標準。
Chang 的個人專業背景是「數學」、「運營研究」、「統計學」。所以他更傾向於把自己定位於 A 型數據分析師,但是與此同時他對 B 型分析師能夠涉及那麽多的工程開發工作而向往不已。
初創公司早期、快速發展的初創公司、以及實現規模化發展的初創公司中的數據分析師職位區別
在選擇投身於科技行業的時候,最經常遇到的一個問題就是到底是加入一個大的科技公司好呢?還是加入一個小的科技公司好。在這個話題上已經有很多爭論了,但是在「數據分析」上麵的爭論並不是很多。所以在本章節要具體談到的是,不同公司的規模、發展階段中,數據分析師不同的角色定位。
處於不同發展階段的科技公司生產數據的量與速度都是不一樣的。一個還在嚐試著尋找到「產品市場契合點」的初創公司完全不需要 Hadoop,因為公司本身就不存在多少的數據需要處理;而一個處在快速發展中的初創公司往往會遭遇更頻密的數據衝擊,也許 PostgreSQL 或者 Vertica 更適合這家公司的需要;而像 Twitter 這樣的公司如果不借助 Hadoop 或者 Map-Reduce 框架,就完全無法有效地處理所有數據。
Chang 在 Twitter 學到的最有價值的一點內容就是:數據分析師從數據中提取出價值的能力,往往跟公司本身數據平台的成熟度有著密不可分的關係。如果你想要明白自己從事的是哪種類型的數據分析工作,首先去做做調研,看看你意向中的這家公司的底層係統架構能夠在多大程度上支持你的目標,這不僅僅對你好,也對公司好,借此看你個人的職業發展目標是否跟公司的需要契合起來。
在初創公司早期,最主要的分析重點是為了實現 ETL 進程,模塊化數據,並且設計基模架構,將數據記錄應用到上麵。這樣數據就能夠追蹤並存儲。此處的目標是打下分析工具的基礎,而不是分析本身。
在快速發展的初創公司的中期,因為公司在快速發展,那麽數據也在不斷的增長。數據平台需要適應不斷發展的新形勢,新條件,在已經打好基礎的前提下,開始逐漸實現向分析領域的過渡。一般來說,此時的分析工作主要圍繞著製定 KPI,推動增長,尋找下一次增長機會等工作展開。
實現了規模增長的公司。當公司實現了規模化增長,數據也開始呈幾何倍數的增長。此時公司需要利用數據來創造,或者保持某種競爭性優勢,比如更好的搜索結果,更加相關的推薦內容,物流或者運營更加的高效合理。這個時候,諸如 ML 工程師,優化專家,實驗設計師都可以參與進來一展拳腳了。
在 Chang 加入 Twitter 的時候,Twitter 已經有了非常成熟的平台以及非常穩定的底層結構。整個數據庫內容都是非常幹淨,可靠的。ETL 進程每天輕鬆處理著數百個「任務調度」工作。(Map-Reduce)。更重要的是,在數據分析領域的人才都在數據平台、產品分析、用戶增長、實驗研究等多個領域,多個重點工作齊頭並進一起展開。
他是在用戶增長領域安排的第一名專職數據分析師。事實上,這花了他們好幾個月來研究產品、工程、還有數據分析到底該如何融合,才能實現這樣一個崗位角色。Chang 的工作與產品團隊緊密連接,根據這方麵的工作經驗,他將自己的工作職責劃分成為了下麵幾類內容:
- 產品分析
- 數據傳輸通道
- 實驗(A/B 測試)
- 建模
下麵將會按照排列次序逐一解釋
產品分析
對於一家消費級科技公司來說,產品分析意味著利用數據來更好地理解用戶的聲音和偏好。不管什麽時候用戶與產品進行著互動,Twitter 都會記錄下來最有用的數據,存儲好它們,以待未來某一天分析之用。
這個過程被稱之為「記錄」(logging)或者「工具化」(instrumentation),而且它還不斷地自我演進。通常情況下,數據分析往往很難實現某個具體的分析,因為數據要麽是不太對,要麽是缺失,要麽是格式錯誤的。在這裏,跟工程師保持非常好的關係非常有必要,因為數據分析能夠幫助工程師確認 bug 的位置,或者係統中一些非預期的行為。反過來,工程師可以幫助數據分析彌補「數據鴻溝」,使得數據內容變得豐富,彼此相關,更加準確。
下麵舉出來了 Chang 在 Twitter 展開的幾項與產品有關的分析案例:
- 推送通知分析:有多少用戶能用得到「推送通知」?不同類型的推送通知具體的點擊率都分別是多少?
- SMS 發送率:在不同的數字載體上,Twitter 的 SMS 發送率都是怎麽計算的?是不是在發展中國家這個發送率相對比較低?我們該怎樣提升這個數字?
- 多賬戶:為什麽在某些國家,一個人持有多個賬戶的比例會相對較高?背後是什麽動機讓一個人持有多個賬戶?
分析會以多種形式展開。有些時候公司會要求你對一次簡單的數據拉取進行最直白的解讀,又或者你需要想出一些新的方式方法來機選一個全新,且重要的運營指標。(比如 SMS 發送率),最後你會更加深刻地理解用戶的行為。(比如一個人擁有多個賬戶)
在產品分析中不斷研究,得到真知灼見,這是一個不斷迭代演進的過程。它需要不斷地提出問題,不斷地理解商業情境,找出最正確的數據組來回答相應的問題。隨著時間的累積,你將成為數據領域的專家,你會正確地估計出來執行一次分析大概得花多長時間。更重要的是,你將逐漸從一個被動響應的狀態,逐漸過渡到主動采取行動的狀態,這其中會牽連出來很多有趣的分析,這些內容都是產品負責人曾經壓根沒有考慮過的,因為他們不知道這些數據存在,又或者不同類型的數據以某種特殊的方式組合到一起竟然會得出如此驚人的結論。
此處需要的技能:
- 保存和工具化:確認數據鴻溝。與工程部門建立良好的協作關係;
- 有能力引導和確認相關的數據組,知道正確使用它們的方式;
- 理解不同形式的分析,能夠在不同的分析執行之前就正確地估算出難易程度,所需時間長短;
- 掌握你的查詢語言。一般來說是利用 R 或者 Python 來實現數據再加工;
數據管道
即使 A 型數據分析師不太可能自己編寫代碼,直接應用到用戶那裏,但是出乎很多人意料的是,包括 Chang 在內的很多 A 型數據分析師確實在給代碼庫寫東西,目的隻有一個:為了數據管道處理。
如果你從 Unix 那裏聽說過「對一係列命令的執行」,那麽一個數據管道就意味著多個係列命令的執行,我們能夠不斷周而複始地自動捕捉,篩選,集合數據。
在來到 Twitter 之前,Chang 的分析絕大部分都是點對點的。在 Chang 的本地機器上,代碼執行上一次或者幾次。這些代碼很少得到審查,也不太可能實現版本控製。但是當一個數據通道出現的時候,一係列的功能就浮出水麵:比如「依賴管理」、「調度」、「源頭分配」、「監控」、「錯誤報告」以及「警告」。
下麵介紹了創建一個數據管道的標準流程:
- 你忽然意識到,如果一個數據組能夠周而複始地自我重新產出,那麽這個世界估計會因此受益;
- 在確認了需求之後,你開始設計「生產數據組」的「數據架構」;
- 開始編寫你的代碼,不管是在 Pig,Scalding,或者 SQL 中。這取決於你的數據環境是什麽;
- 提交代碼,進行代碼審查(code review),準備後得到回饋,並做相應額外的修改。要麽是因為你的設計邏輯不太對,要麽是你的代碼出於速度和效率的目的並沒有優化到位;
- 應該有一個「測試」和「試運轉」的環境,確保所有的運行都在既定的軌道上。
將你的代碼融合到主庫中
建立「監控」、「錯誤報告」以及「警告」等功能,以防止未來出現預期之外的狀況。
很顯然,數據通道比一個點對點的分析工具來說更加複雜,但是優勢也非常明顯,因為它是自動化運行著的,它所產出的數據能夠進一步強化麵板,這樣更多的用戶能夠消費你的數據 / 結果。
另外,更加重要但是往往被人忽略的一點結果是,對於如何打造最優化的工程設計,這是一個非常棒的學習過程。如果你在日後需要開發一個特別定製的數據通道,比如機器學習,之前所做的工作就成為了紮實的基礎。
在此處需要用到的技能:
- 版本控製,目前最流行的就是 Git;
- 知道如何去做「代碼審核」,並且知道如何有效地給予反饋;
- 知道如何去測試,如何去試運行,當出現錯誤的時候知道如何「debug」;
- 「依賴管理,調度,資源分配,錯誤報告,警告」功能的設置。
接下來的篇章中,我們將談到除了 “產品分析” 之外,其餘的三種工作內容,它們分別是:數據傳輸通道、實驗(A/B 測試)、以及建模。
數據管道
通過上文的描述,也許在很多人的概念中 A 型數據分析師不太可能自己編寫代碼,直接應用到用戶那裏,但是出乎很多人意料的是,包括 Chang 在內的很多 A 型數據分析師確實在給代碼庫寫東西,目的隻有一個:為了數據管道處理。
如果你從 Unix 那裏聽說過「對一係列命令的執行」,那麽一個數據管道就意味著多個係列命令的執行,他們能夠不斷周而複始地自動捕捉,篩選,集合數據。
在來到 Twitter 之前,Chang 的分析絕大部分內容都是點對點的。在 Chang 的本地機器上,代碼執行上一次或者幾次。這些代碼很少得到審查,也不太可能實現版本控製。但是當一個數據通道出現的時候,一係列的功能就浮出水麵:比如「依賴管理」、「調度」、「源頭分配」、「監控」、「錯誤報告」以及「警告」。
下麵介紹了創建一個數據管道的標準流程:
1.你忽然意識到,如果一個數據組能夠周而複始地自我重新產出,那麽這個世界估計會因此受益。
2.在確認了需求之後,你開始設計「生產數據組」的「數據架構」。
3.開始編寫你的代碼,不管是在 Pig,Scalding,或者 SQL 中。這取決於你的數據環境是什麽。
4.提交代碼,進行代碼審查(code review),準備後得到回饋,並做相應額外的修改。要麽是因為你的設計邏輯不太對,要麽是你的代碼出於速度和效率的目的並沒有優化到位。
5,應該有一個「測試」和「試運轉」的環境,確保所有的運行都在既定的軌道上。
6.將你的代碼融合到主庫中。
7.建立「監控」、「錯誤報告」以及「警告」等功能,以防止未來出現預期之外的狀況。
很顯然,數據通道比一個點對點的分析工具來說更加複雜,但是優勢也非常明顯,因為它是自動化運行著的,它所產出的數據能夠進一步強化麵板,這樣更多的用戶能夠消費你的數據 / 結果。
另外,更加重要但是往往被人忽略的一點結果是,對於如何打造最優化的工程設計,這是一個非常棒的學習過程。如果你在日後需要開發一個特別定製的數據通道,比如機器學習,之前所做的工作就成為了紮實的基礎。
在此處需要用到的技能:
- 版本控製,目前最流行的就是 Git。
- 知道如何去做「代碼審核」,並且知道如何有效地給予反饋。
- 知道如何去測試,如何去試運行,當出現錯誤的時候知道如何"debug」。
「依賴管理,調度,資源分配,錯誤報告,警告」功能的設置。
實驗(A/B 測試)
此時此刻,非常有可能你現在使用的 Twitter App 跟我手機上裝的 App 是有一點小小的不同的,並且很有可能你在用著一個我壓根沒有見到過的功能。鑒於 Twitter 的用戶很多,它可以將其中很小的一部分流量(百分之幾)導入到一次實驗中,去測試這個尚未全麵公開的功能,去了解這些被選中的用戶如何跟這個全新的功能互動,他們的反響跟那些沒有見到這個功能的用戶進行對比。
這就是 A/B 測試,去讓我們方便測試各種變量,通過 A 和 B 到底哪個方案更好。
Chang 個人的看法是:為一些較大的科技公司做事,能夠享受到的一點優勢,就是能夠從事開發和掌握業界最神秘的技能:「A/B 測試」。作為一名稱職的數據分析師,你必須利用可控製的實驗,在其中進行隨機測試,得到某種確定的因果關係。而根據 Twitter 負責工程部分 A/B 測試的副總 Alex Roetter 的話來說,「Twitter 的任何一天中,都不可能在沒有做一次實驗的前提下就草率放出某個功能。」A/B 測試就是 Twitter 的 DNA,以及產品開發模式的基礎。
A/B 測試的循環周期是這樣的:取樣-> 分組->分別對待-> 評估結果-> 作出對比。這聽上去是不是覺得挺簡單的?其實事實完全相反。A/B 測試應該是天底下最難操作的分析之一,也是最容易被人低估難度的一項工作。這方麵的知識基本上學校是不教的。為了更好的闡述觀點,分了下麵五點內容,分別是五個階段,其中一些部分有可能是你從事 A/B 測試時會遇到的一些困難和挑戰。
- 取樣—?我們需要多少的樣本?每一組分多少個用戶?我們是否能夠讓實驗具有足夠的可信度和說服力?
- 分組—?哪些人適用於出現在這次實驗中?我們從代碼的哪一處開始起手,分出兩個版本?是否會出現數據稀釋的情況?(數據稀釋的意思就是,有些用戶被納入到了新改動的版本測試中,但是實際上他們卻壓根不打開這個 App,見不到這個新變動的功能。)
- 區別對待-整個公司中是否還有其他的團隊在做其他的測試,瞄準的用戶是否跟此時我們鎖定的用戶群發生重疊?我們該怎樣應對「測試衝突」這種情況,保證我們的數據沒有被「汙染」?
- 評估結果-測試的假設前提是什麽?實驗成功或者失敗的指標是哪些?我們是否能做到有效的追蹤?我們是否要增加一些其他方麵的數據存儲?
- 做出比較-假設某個條件下的用戶數量發生了激增,它是不是因為其他的一些因素?我們是如何確保這些統計具有實際的意義?就算具有實際的意義,這個意義對於下麵的產品改良又具有多大的指導作用?
不管回答上述的哪一個問題,都需要對統計學很好的掌握才能辦到。就算你一個人能力很強,但是團隊其他同事還是有可能給這個 A/B 實驗添亂子。
一個產品經理有可能特別心急,沒等試驗結束就要偷窺數據,又或者想當然地,按照他們想象的方式挑選自己想要的結論。(這是人性,別怪他們)。一個工程師有可能忘記存儲某個特殊的信息,又或者錯誤的寫出測試用的代碼,實驗結果出現了非常離譜的偏差。
作為數據分析師,這個時候不得不對自己和他人嚴厲一些,讓整個團隊都能高效、準確地運轉,在實驗的每一個細節上麵都不能有任何的差池。時間浪費在一次徒勞無功,設計錯誤的實驗中,這些時間是找不回來的。甚至還會出現更糟糕的情況,依據一次錯誤的實驗結論形成錯誤的決策,最終給整個產品帶來極大的風險。
在此處所需要用到的技能:
- 假設條件測試: 統計學測試,統計數據可信度,多重測試。
- 測試中有可能出現的偏差: 按照自己想要的結果去推斷結論,延滯效應,數據稀釋,分組異常
預測型建模以及機器學習
Chang 在 Twitter 負責開發的第一個重大項目是將一組「疲勞標準」添加到 Twitter 目前的郵件通知產品中,這樣能夠降低郵箱過濾機製將 Twitter 的信息視為垃圾信息的概率,從而實現讓用戶更頻繁在收件箱中看到 Twitter 發來的電子郵件。
盡管郵件過濾機製不失為使一次偉大的發明,但是郵件通知也確實是提升客戶留存率的特別有效的辦法之一。(這個結論是 Twitter 曾經做的一次實驗中無疑中發現的)。所以,Chang 的目標就是在這其中取得平衡。
在基於上述的觀察和思考之後,Chang 想到了一個點子:觸發式的郵件發送機製。也就是隻有在用戶與產品之間發生了某種互動的情況下,這封郵件才會發送到用戶的電子郵箱。作為剛剛加入團隊的數據分析師,Chang 特別想要通過這個項目來證明自己的價值,於是決定利用非常棒的機器語言模型來預測電子郵件的 CTR(點擊率)。他將一大堆用戶級別的功能集合在 Pig 工具中,並建立了一個隨機預測模型來預測郵件點擊。這背後的想法是,如果用戶在過去很長一段時間內都對電子郵件有著低點擊率,那麽 Twitter 就會保留這封郵件,不再給他發送。
上述的想法都很好,但是隻有一個問題,所有的工作都是放在本地機器的 R 中處理的。人們都很讚賞 Chang 的工作成果,但是他們不知道如何利用這個模型,因為它是無法進一步轉化成產品的。Twitter 的係統底層是無法與 Chang 的本地模型展開對話的。
這一課帶來的教訓讓 Chang 終生難忘。
一年之後,Chang 和增長團隊中的兩個人共同捕捉到了一個全新的機會,能夠打造一個用戶流失率預測模型。這一次,Chang 已經在開發數據管道上有了非常充足的經驗。這一次他們做的非常好,模型能夠針對每一個用戶自動的生成一個用戶流失概率!
幾個星期之後,他們開發了數據管道,並且確認它真的具有很有效的預測能力,他們通過將分數寫入到 Vertica,HDFS,以及 Twitter 內部一個稱之為「曼哈頓」的關鍵價值商店。這樣大家都知道了它的存在。公司無數分析師,數據分析師,工程服務部門都過來試用,進行查詢,幫其宣傳,評價非常好。這是 Chang 在 Twitter 最值得驕傲的一件事,真正把預測模型納入到了產品當中。
Chang 認為絕大部分傑出的數據分析師,尤其是 A 型的數據分析師都存在這樣一個問題,他們知道怎樣去建模,但是卻不知道怎樣把這些模型嵌入到產品係統當中。Chang 的建議是好好跟 B 型數據分析師聊聊吧,他們在這個話題上有著足夠豐富的經驗,發現 A 型和 B 型數據分析師職能重合的那一部分,想想接下來需要的一些技能組合是什麽,這樣才能讓自己在數據分析師的道路上走的更深更遠,更加寬廣。
「機器學習並不等同於 R 腳本。機器學習起源於數學,表達在代碼中,最後組裝在軟件中。你需要是一名軟件工程師,同時需要寫一點可讀的,重複使用的代碼。你的代碼將被更多人重新讀取無數次-來自 Ian Wong 在哥倫比亞數據學課堂上的講座節選。
在這裏所用到的技能:
- 模式確認:確認哪些問題是可以通過建模的方法來加以解決的
- 建模以及機器語言的所有基礎知識:探索型數據分析,開發功能,屬性選擇,模型選擇,模型評估,練習 / 確認 / 測試。
- 產品化:所有上麵的內容有關於數據管道的建立,使得不同的人都能夠在上麵執行查詢
最後的一些話:
成為一個數據分析師確實是一件挺讓人激動的事。你能從別人根本無法達到的角度獲取真相,這足夠酷炫了。從底層開始開發數據管道或者機器語言模型,會給人帶來深層次的滿足感,當執行 A/B 測試的時候,有太多時刻會給你一種當「上帝」的趣味。即便這條路充滿了曲折以及不確定性,有很多挑戰擺在眼前,但是走在這條路上的人永遠不會退縮。任何一個聰明,有想法的年輕人都應該考慮成為一名數據分析師。

首先,數據科學是什麽?數據科學家又是什麽?這本身就是個見仁見智的問題,幾乎每個人都會給你一個不同的答案。所以你能做的隻能是找出自己的理解,就像我隻能提供給你我個人的理解。
本人進入數據分析行當快兩年了,從一開始執著“數據科學家”的名分(因為聽著新鮮有趣,那還是 2013 年下半年呢,嗬嗬兩年過去看世界都變成什麽樣了),到後來一直不斷翻新個人的理解,也算經曆了一個找尋的過程,並且還在找尋中把。
在這個過程中,一開始我也是把注意力集中在“硬”技能上,就是那些常見的技能羅列的東西。這種清單,你可以隨便去 LinkedIn 上搜索一個 Data Scientist 職位,然後在 desired skills 清單裏一抓一大把,你會發現不同公司的要求變化相當大,所以不存在標準答案。然後你可以從數據分析的角度把自己最心儀公司招 Data Scientist 的要求的核心部分給總結一下,看看有哪些核心部分(就是交集啦)。那應該能提供給你一個比在這裏提問更有效的答案。
不過我個人感覺真正的重要的技能還是“軟”技能,也就是把關於行業的了解完全滲透到做數據分析的過程當中去。這裏麵有一個要點,就是始終清楚自己做數據的目的到底是什麽。好比我上麵提到用數據的角度去找出“數據科學家的核心技能集合”,當你做這樣的事情的時候,你完全清楚自己的目的是什麽,使用不管什麽方式方法,你在做的就是一個“目的性明確的數據分析”工作。
現實中充滿了各種各樣的問題,有很多都可以轉化成數據問題來解決。因此我在個人網頁上寫了下麵這句話:
In the world of data mining, there's always an answer to your question
也許通過你自己的道路,你能獲得更我相似或者不同的心得。這是個體成長上的收獲,都是非常值得珍惜的。另外,收了幾本個人感覺收獲最高的數據科學相關書籍在這裏,僅供參考:Data Science

 Quora回答:
Quora回答:

成為一名數據科學家是一個很大的挑戰,我從大四開始用了三四年的時間慢慢轉型到了數據科學的方向,深感這個過程對商科、社科(以及不是計算機和數學方向的理工科)的青年來說有多大的挑戰。數據科學是人類信息技術和數理科學的大融合,其知識密度和知識深度超過了大多數傳統職業,要想從門外從到門內,學會開始駕馭這個龐然大物,有著一座又一座的知識山峰要去攀登,很像是一場創業的經曆,高風險、高回報、很辛苦、但也很快樂。
這幾年我一直在思考這個問題,到底大數據對我們意味著什麽,我們又怎樣適應大數據的時代,我覺得無論是要轉型成為數據科學家,還是掌握數據分析技能,這是我們每一個人的事情。就像馬雲最近說的”數據是未來的石油“,誰都離不開它。我想根據自己的經曆,從挑戰和機遇這兩個角度來談談,怎麽從外行(社科、商科、傳統工科)轉型成為一名數據科學家,幫助更多像我一樣的普通人能夠少走些彎路。
- 大數據時代的技能大挑戰
數學焦慮是人們麵對數學問題時產生的習慣性的焦慮或恐懼情緒,會極大地影響人們解決數學問題的能力,並降低學習數學的興趣。心理學家發現,對於數學的恐懼是一個很普遍的現象。調查反映,美國有60%的大學生都存在著數學焦慮情緒,而僅有10%的學生是對數學感興趣的。從牛頓發明微積分算起,現代數學體係是人類最近300年發展出的一套理論體係。數學符號化、抽象化的運作方式,和人類大腦先天視覺化、具體化的思維習慣有著很大的差異。
數學學習需要學生保持長時間的注意力集中,也就是要坐得住冷板凳,而這一點正在變得越來越困難。美國高度發達的娛樂產業,已經使得多動症成為了高發的兒童心理疾病。美國中學生的數學水平測試,已經遠遠落後於亞洲和北歐的學生。雖然有著高質量的教育資源,但薄弱的數學基礎使得美國大學生不願意選擇理工科專業,僅有20%的美國大學生畢業於理工科。
理工科人才的缺口,已經限製到了美國經濟的發展,迫使奧巴馬在2011年發布了“STEM人才培養計劃”,其中的“STEM”,是科學、技術、工程、數學四個英文的縮寫。BCG在2014年發表的研究報告中發現,美國的高科技行業麵臨著嚴重的人才緊缺。科技產業發達的華盛頓州中,有三分之二的科技高端崗位都無法找到合適的員工。 中國學生的數學基礎教育是全球領先的,但是數學焦慮也同樣普遍。數學基礎課的掛科率在各個院校都排名靠前,而大多數學生對數學課程也缺少興趣。高校的數學係也是報考人數不足,每年都需要通過調劑招生。
數據工作者的門檻不僅在於數學和統計學知識,也在於編程能力和行業經驗。 大數據分析基於海量數據的儲存、傳輸和處理,從原始數據到分析結果,需要運用一係列程序。數據分析常用的軟件包括比如Hadoop、SQL、R、SPSS、Tableau、Excel,很多工作都需要編程的技能。數據分析的目標是發現問題、解決問題、提高效益,但每一個行業都有特定的問題。行業經驗能夠讓數據分析人員找到問題的方向,抓住問題的重點,從而更有效地利用數據,也能夠使分析的結果發揮更大的價值。編程能力和行業經驗多許多大學生,也有著不小的門檻,這更是讓優秀的大數據人才顯得彌足珍貴。
- 全球資源為我所用
教育是一個人最重要的投資,其價值在技術變革的時代更加凸顯。旺盛的需求使得教育成本迅速增長,對於很多家庭,教育已經成為了房產之外最大的負擔。而我們在此前的報告也指出,隨著高校和企業的差距被技術變革迅速拉大,高校所提供的知識和技能已經難以適應生產力要求。大數據時代的轉型升級,前提就是要跟上生產力升級的步伐,充分利用互聯網的力量。 大數據生長在互聯網的土壤之上,數據通過互聯網采集,通過雲計算得到處理,而大數據分析所要教育資源和軟件工具,幾乎全都都能通過互聯網獲得。
教育作為文化產品,其價格和價值之間並沒有必然關係。在傳統課堂中投入過多的資金和時間,並不是最明智的選擇。互聯網教育的發展,讓價值巨大的優秀教育也已成為免費的服務。在Edx、Coursera這些在線教育平台上,全球範圍內最優秀的教育資源,已經免費開放給了全世界的用戶,許多大數據領域的國際專家都在這些平台上開設了免費的學習課程。
優質、免費的教育是互聯網給所有青年的禮物,而大數據領域最前沿的技術,也向所有人免費開源。隻要掌握了使用方法,每個人都可以運用Hadoop搭建數據儲存和計算平台,用R語言進行數據建模和可視化分析。免費的大數據工具功能強大而且性能穩定,在Facebook和IBM這類頂尖企業也被廣泛運用。 分析工具的免費,使得每個人都有了學習和運用大數據技術的機會。大數據工具的迅速普及,車多司機少,駕馭工具的人才就出現了嚴重的供不應求。
吸收大數據分析的知識,應用大數據分析的工具,是實現數據化升級的必要條件。掌握大數據的知識和工具雖然有著很高的學習門檻,但是獲取大數據的教育資源和分析工具的門檻卻已經完全消失。
- 在實踐中贏取持久戰
真正可行的方式,是小處著手,循序漸進,在實踐中學習理論。實踐問題有著具體的場景,理解的成本更低,學習的目標也更明確,從而更容易堅持下去。麻雀雖小,五髒俱全,許多大數據項目的技術相對簡單,卻蘊含著很大的價值。比如銀行業廣泛應用的信貸風險模型,采用了基礎的回歸模型,大幅降低了銀行壞賬和經濟損失。學習大數據,不妨選定一個感興趣的職業方向,在實踐項目中磨練技能,理解理論。在階段性的成果中,不斷獲得成長的動力,在良好的心態中贏取這場持久戰。
隻要用數據思維看問題,實踐大數據技術的機會其實很多。阿裏巴巴的首席數據官,車品覺先生就給出一個精彩而樸實的例子。他看到屬於個人的信息資料,已經遠遠超出了人們的記憶負荷,於是運用大數據的思想,在“印象筆記”中把自己所有的重要資料都進行了係統化地標記和檢索,大幅度提高了工作的效率。 信息化的時代,利用數據創造價值的機會越來越多 ,而通過實踐內化數據化的思維和技能,我們才能真正抓住這樣的機會。我們能用從學會用大數據管理個人數據開始,到Kaggle這樣的平台中參與大數據分析比賽開始,在項目團隊中學習知識,實踐技能。
- 大數據時代的合作精神
我們的高校仍然沿襲著工業化的組織結構,不同知識背景的同學被專業和學院割裂開來,身邊的朋友和自己的背景都十分類似。要想開始大數據的實踐,就必須找到目標一致、又技能互補的合作夥伴。可是怎樣找到一群可以共事的合作者?首先可以加入學校的數學建模社團、數據分析協會,這裏往往聚集了全校數學基礎最紮實的同學。我們也可以尋找有特定技能和背景的同學,組成優勢互補的項目團隊,一起參加大數據分析的比賽。
真正的機會往往是以挑戰的形式出現,大數據帶來的職業挑戰背後,正是絕佳的發展機會。大數據技術要求的數學基礎和編程技能,確實有著很高的學習門檻,然而優質的教育資源、開源的數據分析工具、合作實踐平台,也讓我們擁有了駕馭大數據,實現大價值的機會。 是留在門檻之下,做一個隨時可能被技術替代的舊青年,還是在實踐積累中跨越門檻,成為掌控技術能量的新青年,選擇在我們自己手中。
一些成功的數據挖掘案例一般都是建立在對數據和業務理解足夠深刻,然後加上一些創造性的想法得出,各種高深的算法往往不是關鍵。
那麽問題來了,創造性的想法怎麽來,很多人對著數據一籌莫展,試便了牛b的算法也發現不了價值。其實根源還是在於對領域數據理解的不深刻,缺乏足夠的洞察力。
當然這裏不是說算法,大數據處理的方法不重要,但這些隻是工具,工具必須掌握,但不能過分強調,工具隻有和領域知識結合才能發揮巨大作用
我推薦“清華大數據(微信號:FudanBigData)”的一篇文章:
圖說:成為一個性感的數據科學家,總共分幾步?
“數據科學家” 是二十一世紀最性感的職業。所謂性感,既代表著難以名狀的誘惑,又說明了大家都不知道它幹的是什麽。那麽想要成為一個性感的數據科學家,總共分幾步?
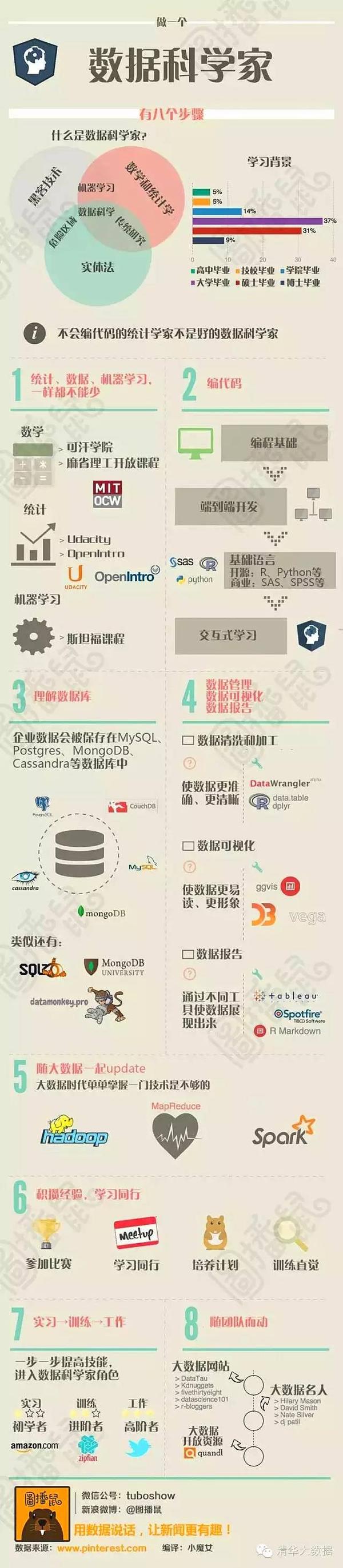

推薦“複旦大數據(微信號:FudanBigData)”的一篇文章:
標題:[譯]從零開始成為數據科學家的9個步驟
由於數據科學和數據分析是迅速發展的領域,從而相應工作的合格人才十分缺乏。這使得對於任何對其有興趣或正在尋找新工作的人來說,數據科學都是一個很有前途且有利可圖的從業領域。

但是,你怎樣才能成為一個數據科學家呢?
首先,對於數據科學科學家的定義不同公司有多種不同的看法。對於這一概念沒有單一的定義。但總的來說,數據科學家是具有統計學知識背景的軟件工程師和在其想要從事的領域具有特定而完備知識的人的複合體。
大約百分之九十的數據科學家至少有大學本科教育背景——更高的具有博士學位,但他們獲得學位的領域十分廣泛。一些招聘人員甚至發現,在人文學科領域有一定創造力的人也可以接受理工科技能。
因此,除了獲得一個數據科學學位(這類學位在世界各地的著名大學如雨後春筍般出現)你需要采取什麽措施成為一個數據科學家?
-
1、 溫習你的數學和統計學技能 。一個合格的數據科學家必須能夠理解數據在告訴你什麽,並通過從數據中獲得的信息進行下一步的工作。你必須有紮實的基本線性代數,對算法和統計技能的理解。在某些地方上可能需要更高級的數學,但這是一個起步的好地方:)。
-
2、 理解機器學習的概念 。機器學習是與大數據有千絲萬縷聯係的新興流行詞。機器學習使用人工智能算法將數據轉化為價值,且無需顯式編程來進行自動學習。
-
3、 學習編程 。數據科學家必須知道如何操作代碼以便告訴計算機如何分析數據。從一個開放源碼的語言,如Python,開始起步是個不錯的選擇。
-
4、 了解數據庫,數據倉庫和分布式存儲 。數據存儲在數據庫、數據倉庫或整個分布式網絡中,這些數據存儲庫建立方式決定了你如何訪問,使用,並分析數據。如果你在構建數據存儲之前不進行整體的考慮將會對你之後的工作帶來深遠的影響。
-
5、 學習數據規整和數據清洗技術 。數據規整是將原始數據轉換成另一種格式以便更容易獲取和分析的過程。數據清理有助於消除重複和“噪聲”數據。兩者都是數據科學家工具箱中的必備工具與技能。
-
6、 了解良好的數據可視化和數據展現的基礎知識 。你不必成為一個平麵設計師,但你需要精通如何創建一個門外漢,如你的經理或CEO,可以理解的數據報告。
-
7、 給你的工具箱添加更多的工具 。一旦你掌握了上麵所說的那些技能,就是時候擴展你的數據科學工具箱了,如Hadoop、R、Spark編程。這些工具的知識和使用經驗將會使你超過大部分想從事數據科學這方麵工作的人。
-
8、 實踐 。在你有一份該領域的工作之前,你如何實踐練習數據科學?你可以使用開源數據進行你自己的個人項目,參加數據科學競賽,通過網絡和數據科學家協同工作,加 入一個訓練營,作誌願者或實習生。最好的數據科學家在該領域應有當有足夠的經驗和直覺,並能夠將他們的工作展示給招聘人員。
-
9、 成為社區的一部分 。關注行業的思想領袖,閱讀行業博客和網站,參與其中,發出提問,並及時了解當前該領域的新聞和理論。
聽起來是不是很多?好吧,確實挺多。數據科學不是適合每個人的,對於對其感興趣並醉心於此的人來說,它可以是令人難以置信的獎勵與回報。如果你沒有足夠的資金上大學,查看一下這下麵個 圖表 ,詳細說明了如何使用網絡上的免費資源完成上麵的這些步驟。

- 作者:Bernard Marr
- 譯者:Tacey Wong
“複旦大數據(微信號:FudanBigData)”的二維碼:


以我現在的理解,其實所謂“數據科學家”,應該更加強調商業上的應用。與其把這個作為一種新的學科、新的知識,不如把它想成一種新的“職業”;這個”商業分析“專業也許沒有對科學的發展、新知識的發現起到多少作用,但是能幫助學生在學習過程中對知識進行整合,從而培養出一種現在公司能用的“員工”。就像我們同學一直自嘲,我們不過是一幫”高級技工“罷了,隻不過這種技工,現在市場需求不小,待遇也不差。


數據科學家與數據分析師
譯注:
1.最近大數據很火,與數據相關的職位在中國越來越為人們熟知,本文介紹了數據科學家與數據分析師的異同。原文鏈接:Data Science vs. Data Analytics
2.文中[]表示為使句子更加通順而添加的一些詞語。
正文:
由於最近這個話題在很多地方被激烈的討論,雖然這篇文章不在計劃內,但我仍然考慮撰寫一篇“數據科學家與數據分析工程師”的文章。
數據科學(Data Science):
我個人對數據科學的理解是這樣的:理解數據和業務邏輯,並通過對當前業務數據進行采樣(分析)來提供預測(也被稱作“數據洞察”、“業務洞察”、“數據發現”、“業務發現”),這些預測是關於業務的走向(好的和壞的)和趨勢的;能夠使業務能夠在走下一步時作出正確的決策。比如:
● 基於用戶興趣級別改進產品/功能
● 吸引更多的用戶
● 吸引更多的點擊、帶來更好的印象、更加方便、帶來更多的收益、吸引更多的潮人(leads?)
● [改善]用戶體驗
● [更好的]推薦
● [增加]用戶停留時間
一般來說,“數據科學”是由“數據科學家”來驅動的,這些人一般是在數學、物理、統計、機器學習或者計算機科學的博士。如果不是這些領域的博士,那麽他很難被雇傭。在最近的ACM的會議裏,一位在線拍賣(online bidding)公司的數據科學人力資源經理在提問環節說她不會雇傭沒有博士學位(和經驗)的人。
數據科學家的職位要求:
● 基本都以“熟悉如何使用數據庫係統(SQL 接口,ad-hoc)、MySQL和Hive”開始[作為最低要求]
● 如果需要的話,還包括Java/python/簡單map-reduce工作開發
● 掌握(Exposure)各種分析方法(超過、中值、排序等),並且知道在各種數據集中應如何使用它們
● 數學、統計學、關聯、數據萬巨額和預測分析(掌握基於概率和關聯的預測)
● “R”或者/和”RStudio”(如excel、SAS、IBM SPSS、 MATLAB)
● 對(統計)數據模型的開發有深入的見解,一般來說當前的主流是自學習模型,這些模型能夠從自己的輸出中進行學習。
● 從事過大數據的相關工作
● 熟悉機器學習和/或者數據挖掘算法(Mahout、Bayesian、Clustering、etc)
在數據科學領域,也有一些其它的職位要求和技能要求,如果能掌握,可能會在候選者中更有競爭力[意譯]。比如,如果你有一個自然語言處理的角色,那麽你可能需要一些不同的技能來匹配這個角色。有時候,這依賴於小組的大小,一個人有時候需要扮演多個不同角色,或者由不同的小組來處理。
目前,市場上對數據科學家有很多需求,可能是僅次於數據分析師的第二大的熱門職位。下麵是數據科學家的需求趨勢:
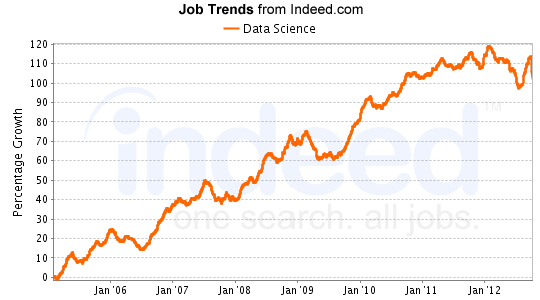
數據分析師
一般來講,數據分析是數據倉庫、商務智能的邏輯上的延伸,它以最有用的形式來提供完整的分析。使用數據倉庫進行分析的最大的不同是,大多數情況下[數據倉庫]分析能夠做到實時,並且動態變化,因為數據倉庫是通過ETL的方式離線處理過的。
任何和數據打交道的業務肯定有“數據分析師”,沒有數據分析師,就像沒有心髒、靈魂和思想的死人一樣。
數據分析(工程)師的職位要求:
● 熟悉數據倉庫和商務智能的概念
● 熟練掌握SQL和相關分析解決方案
● 熟練掌握基於Hadoop平台的分析解決方案(HBase,Hive,Map-reduce jobs, Impala, Cascading等)
● 熟練掌握各種企業級的數據分析工具(Vertica, Greeplum, Aster Data, Teradata, Netezza等),特別是如何使用它們通過最高效的方式來存儲/訪問數據的
● 熟悉各種ETL工具(特別是將各種不同源的數據轉換到分析工具中),來時實時分析變得可能。
● 高效的存儲和訪問數據的模式設計
● 熟悉各種數據體係結構中的工具和組件
● 製定決策的能力(實時和ETL的比較,為實現Z是使用X還是使用Y)
有時候,一名數據分析工程師也在需要的時候扮演數據挖掘的角色[任務],因為他對數據有比別人更好的理解。一半來說,他們為了得到更好的結果會很進行很嚴密的[分析]工作。
數據分析可以分成四種類型或四類角色(因為很難雇傭一個擁有全部技術的人,另一方麵也是因為管理和開發是很不同的)。
● 數據架構師
● 數據庫管理員
● 分析工程師
● 操作員
當前,“數據分析”可能是熱門工作之一(可能Hadoop/大數據工程師超過了它),下麵是在indeed上關於“數據分析”的趨勢,它可能還會繼續熱門下去,因為絕大多數的業務需要及時的數據分析。
即使“數據科學”和“數據分析”在技術領域角度看起來比較相似,但是數據科學更像一個業務單元裏的數據消費者,它依賴數據分析組提供的數據。除此以外,由於更大的數據集上有更好的概率,大多數的模型預測或者算法在大數據集上的運行效果相當好,因此數據越多越好。(有了更多的數據),你就有更好的可能來進行正確的預測,並驅動業務[開展]。這些意味著兩者相互依存。如果你有一個同時掌握這些技能的工程師,那麽你賺到了。
學術一點的:如何變成數據科學家或者數據分析工程師
● 美國大多數的高等學府提供“數據科學”和“數據分析”的課程,其中包括Berkeley、Stanford、Columbia、Harvard等。
● 這裏有一些大學開設的相關課程的鏈接(可能不全也不準確,最好是直接去他們網站上找):
○ Graduate Programs in Big Data Analytics and Data Science
● 這裏還有一個在線的資源:
○ Data Science and Big Data Analytics Training
最後,歡迎關注我的微信公眾號,關注大數據、可視化、挖掘:

用戶3770845573_新浪博客
補充一點:大數據時代,數據科學家必須了解大數據技術,另外 還有一些相關領域:
物聯網,雲計算, 我個人認為其關係可以總結如下:
物聯網=sensor+大數據+雲計算