昨天李飛飛團隊用不到50刀的成本訓練出跟OpenA1-o1和DeepSeek一樣水平的模型,在網上迅速傳開。
前段時間興奮了很久用低成本隻花600萬做出DS,而李飛飛團隊的S1隻花了不到50刀,就做出同樣水平的東西。
很多人覺得不可能,咋不可能呢?
我一直在說DS的低成本沒啥可吹的:在別人的模型基礎上,用好的訓練數據,加上點工藝,當然能低成本了
現在李飛飛團隊用50刀成本訓練出來,好像倒是可以吹一下,
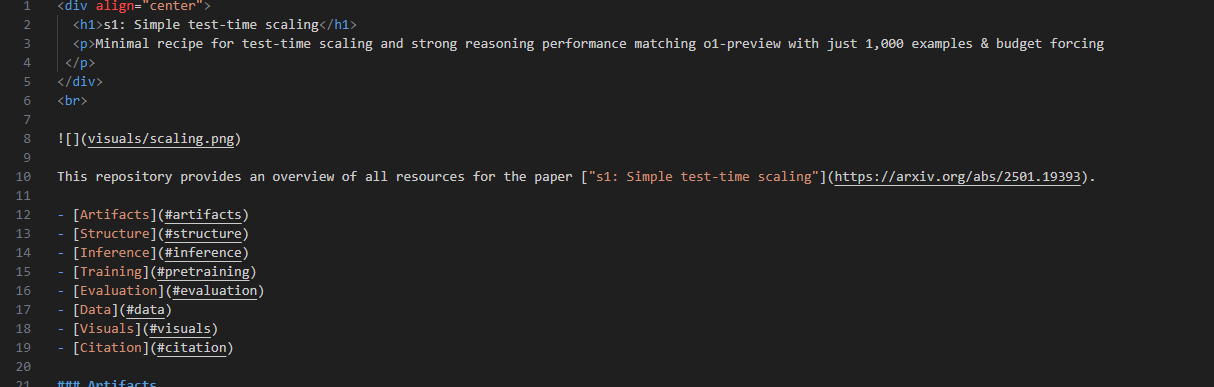
我大概看了一下李飛飛團隊s1論文,大概就是下麵這個樣子,對比一下DS,是不是很類似?
李飛飛團隊的S1 = 阿裏雲Qwen2.5模型為基礎 + 測試時間縮放訓練新方法(1000個精心策劃微小數據集)+ 在雲計算蒸餾出來(雲計算成本低於50刀)
DS = Meta 模型為基礎 + OpenAI數據集(被懷疑)+ 自己的方法 + 花600萬蒸餾出來
s1秘訣是什麽?用了一種名為 “預算強迫 ”的技術,再加上監督微調(SFT)技術,在一個經過精心策劃的、隻有 1000 個示例的微小數據集上實現。
1000個精心策劃微小數據集(訓練數據),和“預算強迫 ”的技術(工藝)是關鍵。
今天早上,下載了s1的代碼看了一下,訓練s1需要的模塊和庫,竟然還有openai,