泥土的氣息
泥土也有生命氣息



Source: https://atscaleconference.com/calling-relay-infrastructure-at-whatsapp-scale/?
WhatsApp 曆史和規模
自2015年推出 WhatsApp 的通話功能以來,它的通話中繼基礎架構一直負責在用戶之間高可靠、低延遲地傳輸語音和視頻數據。從一對一語音通話開始,接著是視頻通話,再到群組通話,WhatsApp 的使用量隨著時間呈指數級增長。該應用現在已成為世界上最大的通話產品之一,每天傳輸超過10億次通話。由於規模如此驚人,我們遇到了很少有通話產品會遇到的獨特問題。我們不斷發展中繼架構,以跟上不斷增長的規模和容量需求。
WhatsApp 原則
WhatsApp 建立在隱私、簡單和可靠性這些核心原則之上。
為確保不可被破壞的隱私,WhatsApp 早期就決定對所有通信(包括語音和視頻通話)強製執行端到端加密。這意味著中繼服務器無法訪問流經其中的媒體內容,因此中繼無法對媒體進行升級/降級、轉碼或任何其他修改。
為確保簡單性,我們專注於通過聚焦並完善最重要的功能為用戶提供無幹擾體驗。從用戶界麵到服務器架構,一切都遵循這一原則。我們自定義的 WASP(WhatsApp STUN 協議)就是一個例子。用戶設備與中繼服務器通信的標準協議是 TURN。TURN 是一種相當複雜的協議,使用多個臨時端口、無法很好地與防火牆配合使用,並且在分布式架構中無法很好地擴展。WASP 的核心與 TURN 相似,但 WASP 僅使用一個端口進行所有網絡通信,並更多地依賴用戶設備來做出決策和跟蹤連接狀態,這對於中繼服務器故障轉移來說效果很好。
為確保可靠性,我們的目標一直是確保任何人都可以撥打 WhatsApp 通話——無論是在高速網絡上使用最新設備,還是在網絡狀況不佳時使用低端設備。我們希望通話功能可以可靠運行,即使在極端負載時,因為那可能是人們最需要與親朋好友聯係的時候。
什麽是通話中繼?
兩個關鍵的基礎設施可以讓 WhatsApp 用戶進行通話:信令服務和通話中繼服務。
信令服務器協助設置通話的初始過程。當有人撥入時,它負責讓設備響鈴;當用戶接聽時,它負責連接通話。
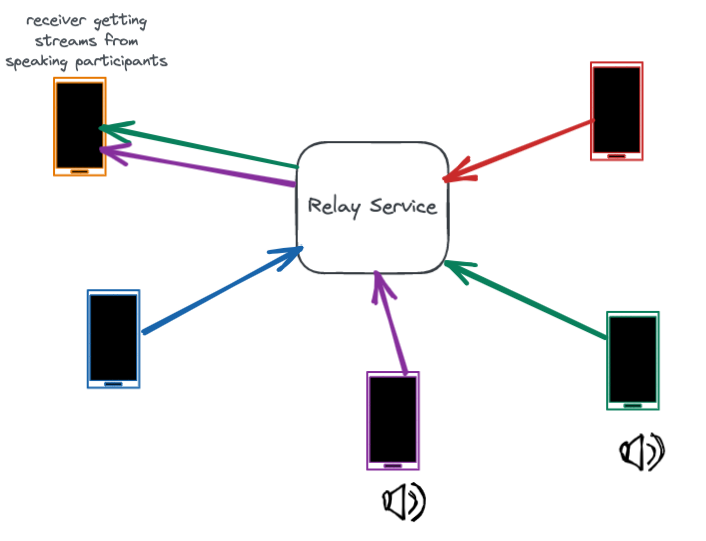
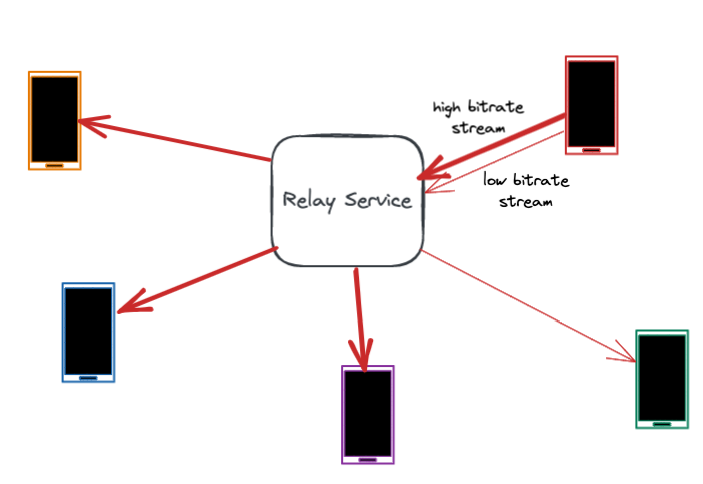
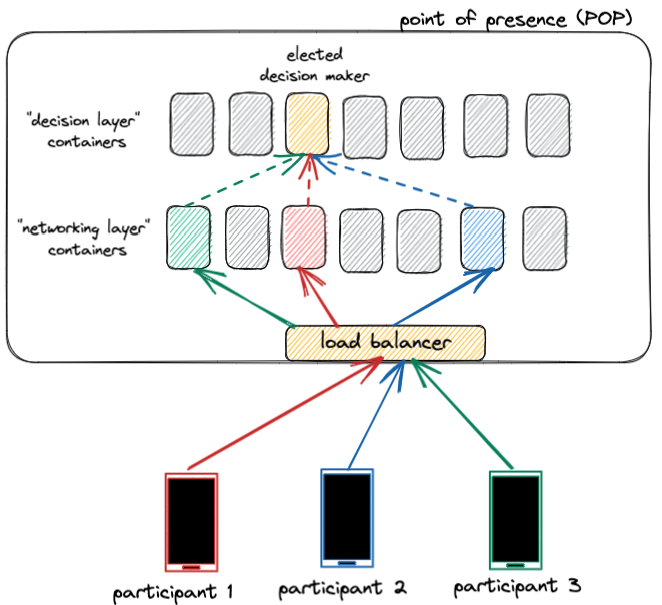
一旦通話建立,中繼服務在整個通話期間起到維護連接的重要作用。通話中繼在用戶設備之間來回傳輸音頻和視頻數據包。
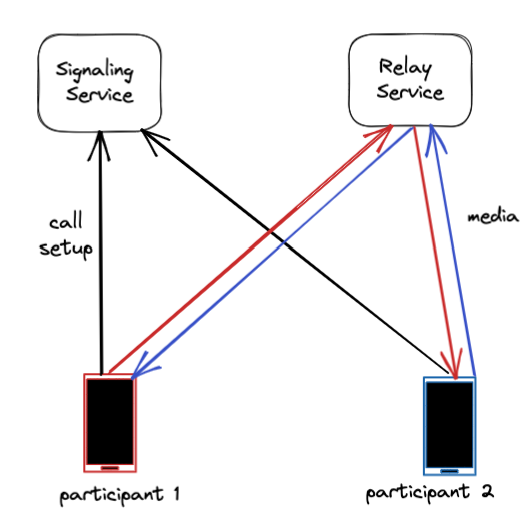
通話中繼解決了與建立 WhatsApp 通話相關的一些關鍵技術挑戰。
改善網絡延遲和數據包損失問題
最好的通話應當像親自交談一樣對話自然流暢,沒有延遲或中斷。這是我們為每次通話所追求的終極目標。兩個關鍵的技術挑戰會影響通話的臨場感:網絡延遲和數據包損失。
網絡延遲會導致對話滯後,幹擾對話的自然流暢度。延遲還會大大降低通話算法的最優運行,因為它們最終會在過時的信息上運行。
數據包損失會導致視頻凍結、音頻機器人化等問題,嚴重影響通話體驗。
延遲
改善延遲的最佳方式是通過盡可能最短的路徑路由通話——這意味著將中繼服務托管在離終端用戶盡可能近的位置。
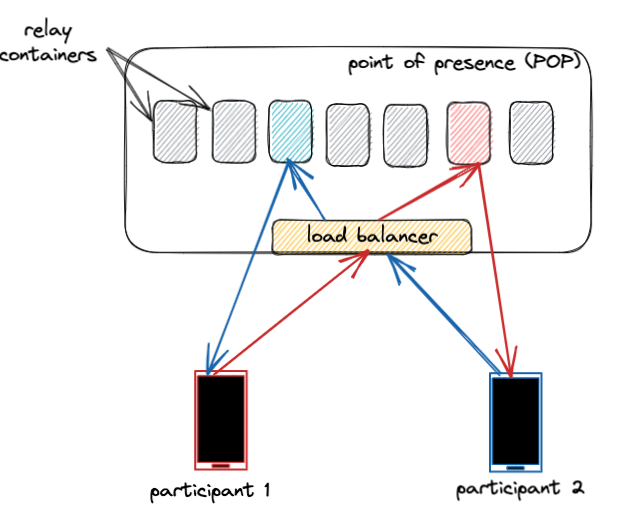
為此,我們設計了WhatsApp中繼基礎設施,使其可在Meta在全球各地建立的數千個接入點(PoP)上運行。這些PoP最初是為了服務於Meta的內容交付網絡(CDN),能夠滿足Facebook和Instagram等產品對其提出的大規模需求。
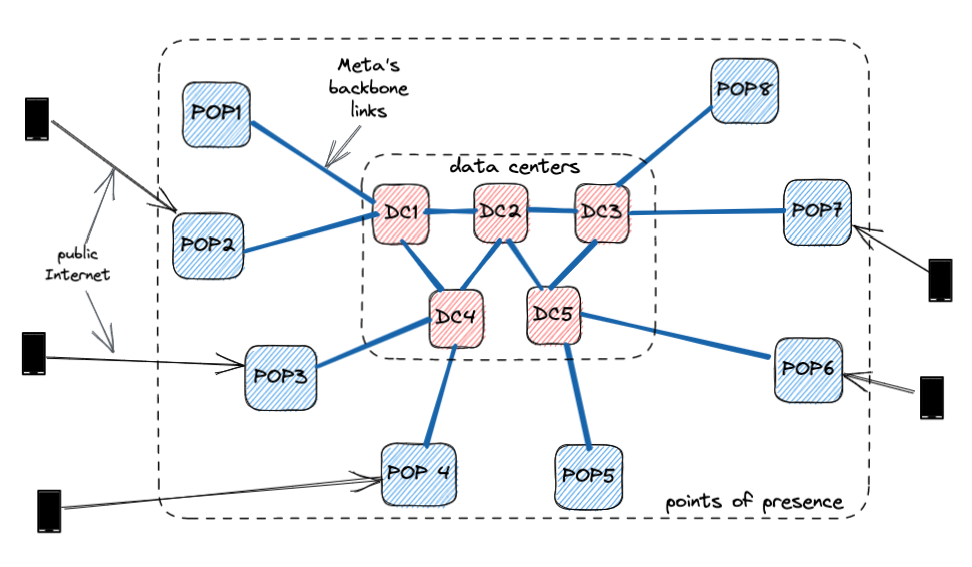
由於這些接入點分布在比數據中心更多的區域,中繼服務距離終端用戶更近,從而降低了WhatsApp通話的延遲。另外,這些接入點集群通過極高質量和專用主幹鏈路互聯。
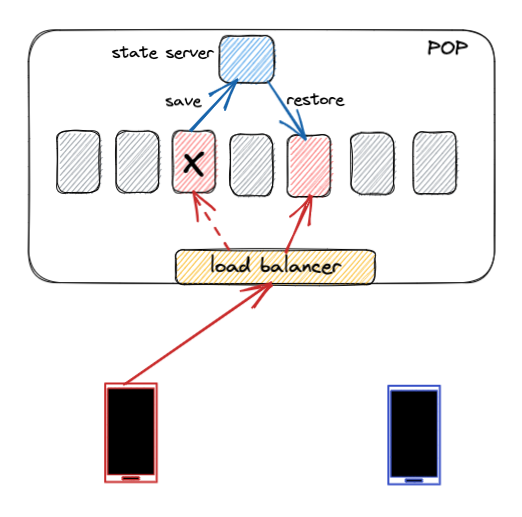
僅靠近終端用戶是不夠的;我們還必須為每次WhatsApp通話選擇最佳集群。為此,我們對曆史延遲數據應用複雜的定位算法,計算出每次通話的最佳集群。通話過程中,最優集群可能會發生變化——例如,當用戶從WiFi切換到蜂窩網絡時。如果我們檢測到正在進行的通話條件發生顯著變化,我們會重新計算最優集群。
數據包損失
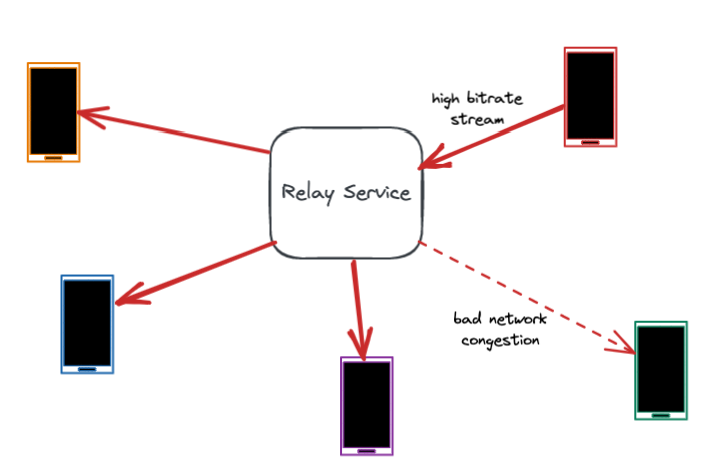
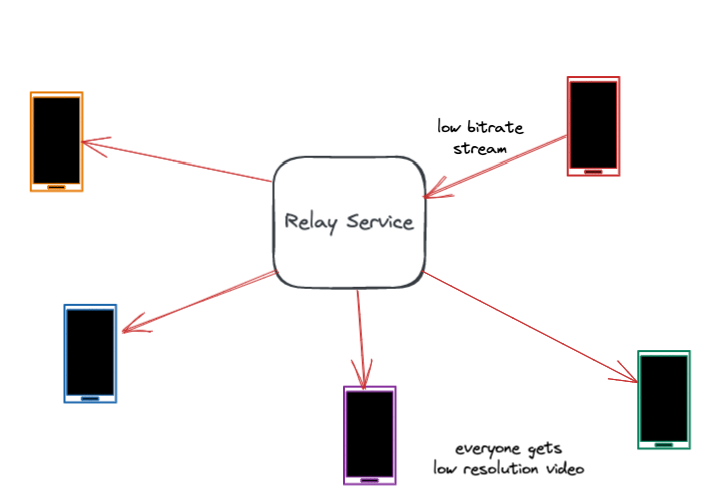
解決數據包損失的最佳方式是防患於未然。大多數數據包損失源於網絡擁塞,而擁塞是由於帶寬使用不當(發送太多數據)造成的,通常是由於不準確地估計網絡鏈路帶寬所致。因此,準確估計帶寬和調節比特率是防止擁塞的關鍵。
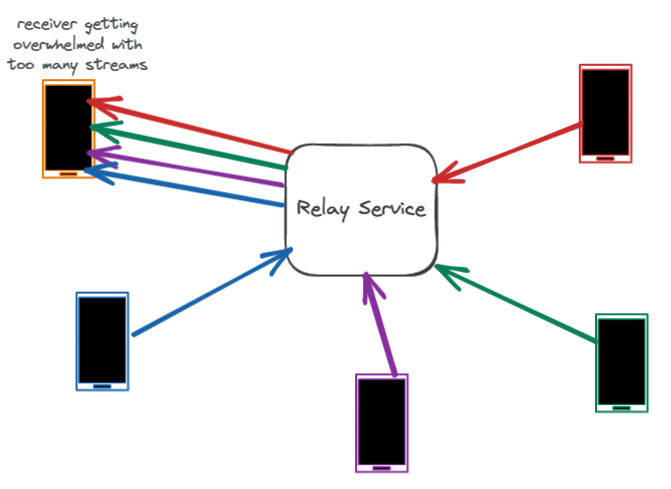
然而,帶寬是高度可變的,在通話過程中會發生波動。許多數據包丟失和帶寬問題發生在最後一公裏,比如用戶的WiFi網絡中。中繼服務器協助準確估計每一段通話的帶寬。它通過測量數據包延遲和數據包丟失,並將這些作為反饋共享給用戶設備。快速準確地估計帶寬有助於設備調整比特率,減少網絡擁塞和數據包丟失。
某些網絡無論是否擁塞都會導致數據包丟失。在這種丟包網絡中,中繼服務使用主動數據包丟失緩解技術。其中一種技術稱為NACK(否定確認)。中繼服務器會緩存幾秒鍾的媒體數據包,並響應設備發送的NACK重傳這些數據包。與端到端重傳相比,從中繼服務重傳效率更高,因為中繼位於通話參與者之間的中間位置,減少了重傳的延遲。另外,中繼更有效率,因為它能夠隻在丟包的鏈路上重傳數據包。