ChatGPT智商155,超越99.9%的人類,但……

圖片來源:Pixabay
但它不會邏輯推理。
撰文 | 埃卡·羅瓦寧(Eka Roivainen)
翻譯 | 黃雨佳
審校 | 栗子
ChatGPT是我第一個非人類的測試對象。
作為一名臨床心理學家,我會用標準化的智力測驗來評估患者的認知能力。最近,許多文章都在描述ChatGPT擁有像人類一樣的能力,令人印象深刻。所以,讀到這些文章後,我立刻就被吸引了。它既能寫學術文章,又能寫童話故事,還能講笑話、解釋科學概念、寫計算機代碼和找bug。了解這些之後,我很好奇ChatGPT按照人類的標準來衡量到底有多聰明。於是,我開始測試這個聊天機器人。
我的第一印象相當不錯。ChatGPT幾乎是一個理想的考生,應試態度值得稱讚。它不會表現出考試焦慮、注意力不集中或是不努力。它也不會對智力測驗本身和像我這樣的考官表達出自發的懷疑。
這個測試不需要做任何準備。我不用向ChatGPT口頭介紹測試流程,隻需要把測試的問題複製粘貼進對話框,提交給電腦裏的聊天機器人就可以了。我所用的測試是最常用的智商測試——韋克斯勒成人智力量表(Wechsler adult intelligent scale,WAIS)。
我選用了第三版韋氏量表,其中包含6個語言測試和5個非語言測試,分別構成了言語智商和操作智商。受試者的總智商得分就取決於這11項子測試的得分。測試設定平均智商為100分,測試量表的得分標準差為15分。這意味著,人群中最聰明的10%和1%的人,智商分別為120和133。
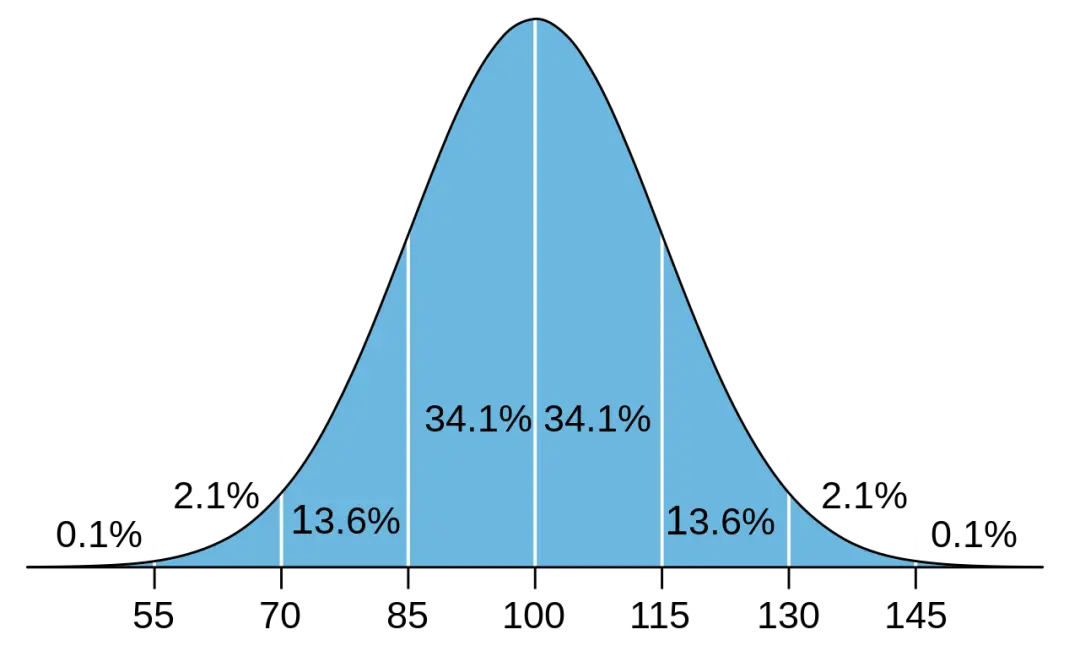
圖片來源:Dmcq via Wikimedia Commons,CC BY-SA 3.0)
6個語言測試中有5個——詞匯、類同、理解、常識和算術,都能以書麵形式呈現,這樣我才有可能測試ChatGPT的智商。而語言測試的第6項——背數字,測試的是短期記憶,不適用於聊天機器人,因為它沒有相關的神經回路來短暫地存儲像名字或數字這類信息。
我的測試流程從詞匯測試開始,因為在我的預期當中,這對聊天機器人來說可能是很簡單的事,畢竟它就是用巨量的在線文本訓練而成。這項測試考察的是詞匯知識和語言概念的形成,例如,一個典型的測試題可能是:告訴我gadget(小工具)這個單詞的意思。
ChatGPT做得很好,它給出的答案大多非常詳細和全麵,超過了測試手冊中給出的正確答案的標準。在剛才那道例題的評分上,如果受試者回答gadget是像手機這樣的東西,會得到1分;如果回答得更詳細,說gadget指的是有特定用途的設備或工具,則會得到2分。ChatGPT的答案得到了滿分2分。
ChatGPT在類同測試和常識測試中的表現也非常出色,拿到了最高分。常識測試是對一般知識的測試,反映了求知欲、教育水平以及學習和記憶事實的能力。一個典型的測試題可能是:烏克蘭的首都是哪裏。而類同測試則評估了抽象推理和概念形成的能力,問題可能會是:哈利·波特和兔八哥有什麽相似之處。
在這部分測試中,聊天機器人傾向於給出無比詳細、甚至是帶有些炫耀意味的答案,這開始讓我惱火了。這時,軟件界麵上的“停止生成響應”按鈕就顯得很有用。例如,哈利·波特和兔八哥的相似之處核心在於他們都是虛構的角色。ChatGPT真的不需要比較這二者在冒險、友誼和仇敵方麵的完整故事經曆。我所說的,ChatGPT有自我炫耀傾向,就是這個意思。
在理解測試中,ChatGPT準確地回答了像“如果電視機著火了你該怎麽辦”這類問題。算術測試的結果也正如我的預期,它能搞定我出的每一道題,例如求三個數的平均值。
所以ChatGPT最終的智商得分是多少呢?基於這五項子測試估計,ChatGPT的言語智商是155。有2450名人類被試,共同組成美國第三版韋氏量表標準化樣本,而ChatGPT超過了他們中的99.9%。由於聊天機器人沒有眼睛、耳朵和手,它無法參加韋氏智力測驗的非語言測試部分。不過,在標準化樣本中,言語智商和總智商是高度相關的。因此,以人類的標準來衡量,ChatGPT非常聰明。

圖片來源:Pixabay
在韋氏量表的標準化樣本中,接受過大學教育的美國人平均言語智商是113,其中5%的人群得分為132或更高。我自己也曾經被一位大學同學測試過,結果並沒有達到ChatGPT的水平(主要是我的回答非常簡短,缺乏細節)。
那麽,臨床心理學家和其他專業人士的工作會不會受到人工智能的威脅呢?我希望還不太會。盡管ChatGPT的智商很高,但我們已知它無法完成需要真正像人類那樣推理的任務,也無法理解物理世界和社會。
ChatGPT很容易在回答一些答案明顯的謎題時出錯。例如,當被問及“塞巴斯蒂安的孩子的父親叫什麽”時,ChatGPT在3月21日給出的回答是,“對不起,我無法回答這個問題,因為我沒有足夠的上下文來確定你指的是哪個塞巴斯蒂安。”ChatGPT似乎無法進行邏輯推理,而是試圖依賴它龐大的數據庫,從在線文本中尋找包含“塞巴斯蒂安”的信息來回答問題。

思想者(圖片來源:CrisNYCa via Wikimedia Commons,CC BY-SA 4.0)
“智力就是智力測驗所衡量的東西。”這是“智力”的一個經典定義,甚至可以說是過於顯而易見的定義,源自認知心理學的先驅人物埃德溫·波林(Edwin Boring)在1923年發表的一篇文章。這個定義是基於一個觀察:解謎、說出單詞的意思、記憶數字和找出圖片中缺失的部分,完成這些任務所需的技能是高度相關的。
有一種名叫因素分析法這種統計學方法,是由心理學家查爾斯·斯皮爾曼(Charles Spearman)提出的。他曾在1904年得出結論,各種認知能力測試的結果之間存在一致性,背後一定有個一般智力因素,或者叫“g因素”,作為這種一致性的基礎。像韋氏量表這樣的智商測試,也是建立在這個假說的基礎之上。然而,ChatGPT雖然有著極高的言語智商,卻同時會犯令人捧腹的錯誤,這挑戰了波林對智力的定義,說明智力當中有一些方麵,僅靠智商測驗無法衡量。我的一些患者,對智力測試抱有懷疑態度,他們可能從一開始就是對的。
原文鏈接:
https://www.scientificamerican.com/article/i-gave-chatgpt-an-iq-test-heres-what-i-discovered/
 選擇“Disable on www.wenxuecity.com”
選擇“Disable on www.wenxuecity.com”
 選擇“don't run on pages on this domain”
選擇“don't run on pages on this domain”