癌症的一些切身體會(八)預測癌症的發生
平等性
前麵幾篇講了癌症的預測,以及預測因子和生物標誌物,有朋友提到了最近頗為流行的液體活檢,並問我液體活檢和生物標誌物有什麽關係。這一篇我先來談談液體活檢的事兒,再介紹一下關於癌症的預測模型。
根據教科書上的解釋,液體活檢是指一種從血液等非實性生物組織中取樣並分析,主要用於診斷或監測腫瘤疾病的方法。液體活檢的主要檢測指標,是血液中的循環腫瘤細胞(circulating tumor cells, CTC)和循環腫瘤DNA(circulating tumor DNA, ctDNA)。因為CTC和ctDNA直接與腫瘤有關係,因此我們可以通過血液取樣,利用細胞分離和測序技術,使用液體活檢技術來幫助醫療工作者估算CTC和ctDNA的數量,這樣就能夠顯著提高腫瘤的預測精度和治療的準確性。
因為液體活檢技術主要是通過抽取患者的外周血液進行檢測分析並獲得腫瘤的相關信息,這樣就不會對被檢測者造成任何創傷,操作起來也方便快捷,而且能夠反複取樣,易於實時檢測和監控。從血液中獲得的CTC和ctDNA可以是來源於實時的腫瘤組織的任何部分,同時也包含了異質性的各個方麵,因此能夠更全麵地反映腫瘤的全貌。有研究顯示,CTC和ctDNA攜帶的信息各有側重,其中ctDNA相比較CTC會更實時,更能夠動態地反映人體內腫瘤的變化情況,所以在現有的癌症預測中使用得最為廣泛;不過CTC也非常重要,它不僅包含了DNA信息,還有RNA和蛋白質信息,因此能夠全方位地揭示腫瘤特征。總的來說,這兩者的相互結合,對於癌症預測的作用更大。
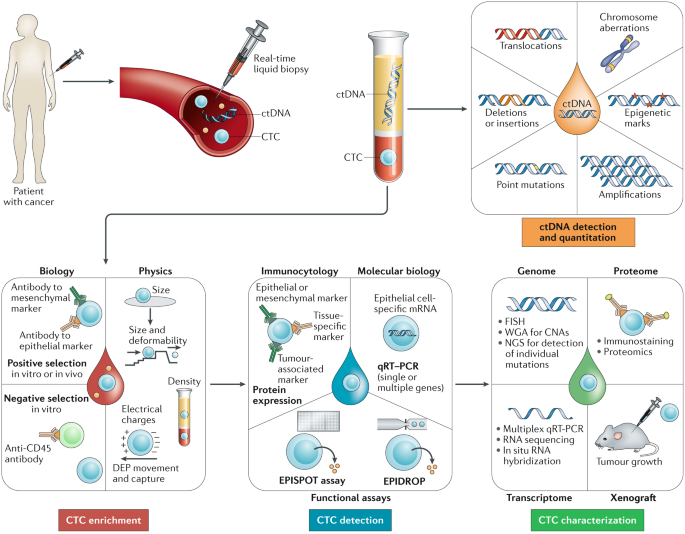
通過前麵的介紹,我們可以看出液體活檢是一整套生物信息技術,它所提取的CTC和ctDNA其實也是屬於生物標誌物的範疇。而不管是利用液體活檢,還是利用其它生物標誌物進行癌症的預測和確定精準治療方案,都需要用到我前麵幾篇所提到的統計模型和機器學習的方法。
大家可能都聽說過數學模型,也就是用抽象化的數學公式去描述現實世界的規律,最有名的幾個數學模型,有勾股定理,牛頓的三大定律,麥克斯韋的電磁方程組,愛因斯坦的質能公式,等等。這些都是在理想情況下,將確定性的規律定量化的經典。但是,在實際生活中,還有很多的規律是具有不確定性的。比如說,天氣變化,量子態的分布,股市起伏,以及和這一個係列有關係的,癌症的發病率和生存預期。
對具有不確定性的規律進行歸納和總結,就需要用到統計模型。而統計模型的基礎,一個是數據,一個是概率。研究概率是對生活智慧和經驗的總結,是個極其實用的法門,我們日常的生活中其實也在不自覺的運用概率而幫助我們的決定。比如說天陰了出門要拿傘,打雷了就最好不要出門,甚至在疫情期間去人多的地方戴口罩,都有一個根據概率做出相應決定的過程。
概率的基礎就是差異和分布,通俗的說就是多種可能性。最簡單的例子就是拋硬幣,有可能是正麵,也有可能是反麵;複雜一點的是擲骰子,一到六,哪一麵都有可能。這個就叫差異。簡單點說,就是即使給足了條件,也不會隻有一個結局,這個是和決定論的最大不同。然後就是分布,也就是每一麵出現的可能性。
建立統計模型,就是需要在收集的數據基礎上建立概率分布的模型,然後根據這個模型去計算具體的概率分布值,並作出相應的判斷和執行。有一些人因為不確定性,就走向了不可知論。他們的理論是,既然事情的真相或發展都有不同的可能性,那麽不如什麽結論都不做,反正怎麽也說不準。這個當然不對,因為如果能深入了解不確定性,並且能夠量化概率並總結出規律,是可以有效幫助我們作出最優化判斷與決策的。在進行癌症預測的時候,我們就是基於曆年收集來的所有致癌因子和生物標誌物,建立一套最符合實際發生率的統計模型,並對新的樣本進行預測,來精確計算發病的概率。
這是統計模型,那什麽又是機器學習呢?機器學習和傳統的統計模型其實是有很多交叉的,一般來說,機器學習是建立在大樣本和高維數據的基礎上,運用更複雜的計算方法,包括了一些人工智能的算法,來建立預測模型的,比如說,決策樹,隨機森林,神經網絡或深度學習神經網絡,蒙特卡洛方法,等等。也就是說,統計模型和機器學習的最終目的,在癌症預測這一點上是一致的,都是為了提供更精確的癌症預測。

正因為癌症的預測是基於統計模型和機器學習,所以它們所得到的,都是概率判斷。概率判斷並不能保證百分百的正確,但是它們可以顯著提高預測的成功率。有些學術界的人士對這些預測模型有所質疑,尤其是擔心那些關於預測的假陽性,假陰性,以及相關的成本和風險是否超過了挽救實際壽命的可能收益。為什麽呢?這是因為建立這樣的預測模型,必須進行回顧性研究,並收集和存儲大量的患者和健康人群的數據。這樣的研究,往往非常燒錢,因此這些大型的研究幾乎從未由私營部門完成,基本上都是由政府提供讚助。因此,用於早期檢測大多數癌症的血液測試的使用範例在幾十年內進展甚微。比如說,在美國,PSA仍然是唯一廣泛使用的用於癌症篩查的血液試驗,且甚至其使用已成為有爭議的。在世界上其它地區,尤其是遠東地區,檢測各種癌症的血液檢測更為普遍,但幾乎沒有標準化或經驗性方法來確定或改善世界這類地區這類測試的準確性。

我自己的看法是,研究都是一步一步的向前發展的,總的來說,統計模型和機器學習係統對於分析信息,幫助我們進行癌症預測和判斷,是起到了顯著成效的。不過盡管現在已經開發了很多的癌症預測和決策係統,但是這樣的係統在醫療實踐中並未廣泛使用,而且因為這些係統遭受了限製,從而無法將其融入到衛生組織的日常操作中。其它還有一些具體實施中的難點,比如說患者數據的錄入繁瑣,需要檢查的項目太多太昂貴,預測模型背後的機理不太透明,等等。
現在的液體活檢,對預測全癌(overall cancer)的敏感性和特異性都達到了相當高的精度。當然,液體活檢技術目前也存在著很多局限性,比如說,液體活檢對區分不同癌症的精確度也還有很大的提升空間,而且無論CTC還是ctDNA在血液中都極其微量,需要更好的技術來增加儀器檢測的靈敏度。現在液體活檢的使用成本較高,應用範圍不廣,主要還是在實驗室的研究階段,到臨床的大規模應用還有很長一段路要走。將來液體活檢在癌症的早期診斷中究竟能達到多及時?液體活檢揭示腫瘤動態變化的反應有多靈敏?對每個特定種類癌症的敏感性與特異性如何?它與現在做為金標準的病理組織活檢的相關性有多高?這些都是當前液體活檢技術亟待解決的問題。
我自己覺得液體活檢是個非常有前景的方向,使用血液測試的方法和技術所收集的數據,建立並提供更多更精確的統計模型和機器學習係統,可以極大程度的幫助癌症的早期檢測和預測。
(本文圖片來自網絡)
癌症的一些切身體會(九)
|